Vue.js es un framework para crear interfaces de usuario, muy parecido a Polymer y a la vez a React, pero también tiene cosas de Angular. Es un framework relativamente pequeño al que puedes ir adaptando a tus necesidades y hacerlo mucho más robusto a través de librerías y herramientas modernas como webpack.
Es uno de los frameworks mejor documentados y con la menor curva de aprendizaje, así que si no tienes experiencia utilizando algún framework parecido, este es el primero que recomiendo que aprendas.
Interpolación
Para empezar a utilizar Vue.js juega con este ejemplo donde creamos nuestra primera implementación con Vue.
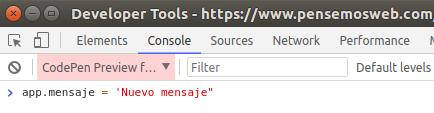
Si nos damos cuenta la propiedad mensajeof the object dataha sido pintada, pero no solo se pintó data.mensajeen la página, sino que tanto el DOMcomo dataestán enlazados y se comportan de manera reactiva, ¿Cómo lo sabes?, en el código guardamos una instancia de Vue en una variable llamada app, esta variable está definida globalmente, por lo que si damos click derecho sobre la página que nos genera codepen, es la parte derecha con fondo blanco y dice Hola soy Vue.js, luego Inspeccionar elementoy nos vamos a la pestaña consola(console), podremos obtener la referencia a esa instancia y modificar sus datos.
Inténtalo de esta manera:
app.mensaje = 'Nuevo mensaje';
Deberás ver en la página como el texto se actualiza automáticamente reaccionando al cambio. Por el momento recuerda que los elementos del datareaccionan al cambio en el DOM y/o directamente cambiando el valor en el código.
Lo que hicimos con {{}}se le llama interpolación, es decir, realiza la operación necesaria para obtener el resultado de mensaje. En este caso nos regresa un resultado en forma de una cadena, podemos utilizarlo también en atributos.
Interpolación en atributos y directivas
Ahora la interpolación se hizo a través de un atributo raro v-bind, a este tipo de atributos se les llama directivas, una directiva son atributos creados por Vue y tienen el prefijo v-, estas directivas aumentan el funcionamiento de un determinado elemento, en este ejemplo pudimos aumentar el funcionamiento del atributo titleen el elemento spanpara que muestre la propiedad mensajede manera reactiva cuando pasamos el cursor del mouse. En otras palabras, se crea un enlace de comunicación el cual permite actualizar la información.
Directiva condicional v-if
Ahora veamos una directiva muy útil v-if , que nos permite pintar o no un elemento basándose en una condición de nuestra aplicación.
Esta interpolación recibe un valor falso, es decir, un valor que se convierte en un boleano false, aquí te dejo una lista de estos valores. Importante, todos los valores que no estén en la lista se convierten en valores verdaderos cuando se ejecutan en una condición.
false
null
undefined
0
cadena vacía “”
El numero NaN (Not a Number)
Directiva repetidora v-for
Esta directiva, muy parecida al forde Javascript te permite iterar sobre los elementos de un arrayo un object.
Al igual que el primer ejemplo, puedes acceder a la variable global appy cambiar el valor de buenosHabitospara que la lista con v-forreaccione a los nuevos datos.
app.buenosHabitos = ['Ir a nadar', 'Dormir temprano'];
Interacción con el usuario usando v-on y v-model
La directiva v-onpermite agregar escuchadores de eventos a elementos HTML, y definir que método de nuestra instancia de Vue ejecutar cuando se dispara el evento. A nuestra instancia le podemos agregar métodos en su propiedad methodscomo se ve en el ejemplo:
También en el ejemplo usamos la directiva v-model, la cual nos permite actualizar los datos en dos direcciones, es decir, desde el input y hacia él, si cambiamos su valor, se refleja como se actualiza el texto que aparece después del botón, y también si oprimimos el botón, vemos como el cambio se refleja en el input y en el texto al revés.
Espero y te sirva este post, comenta si así lo fue y que tipo de temas te gustaría que se explicaran en futuros artículos.
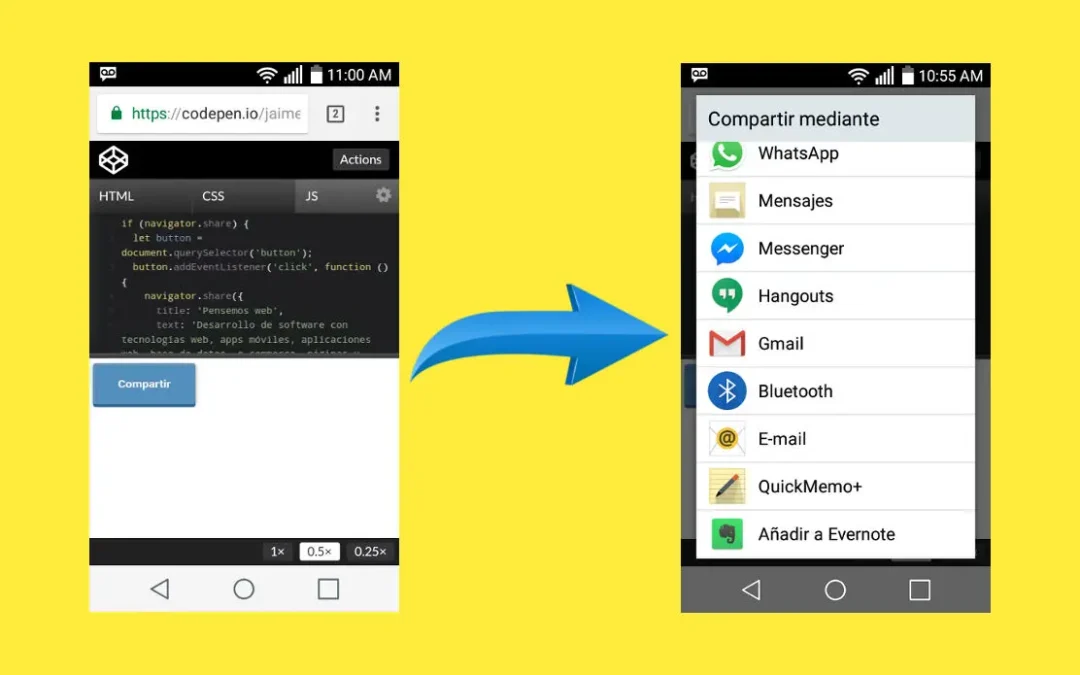
En la versión de Google Chrome 61 para Android se agregó esta interesante funcionalidad que te permite compartir información en redes sociales utilizando las aplicaciones nativas de tu smartphone.
¿Cómo se usa?
Para poder utilzar esta Web share API, necesitas:
Chrome 61 o una versión mayor en Android
Que la aplicación o sitio web funcione sobre el protocolo seguro HTTPS
Aqui esta un ejemplo, pruebalo en tu android con Chrome 61 o una versión mayor, de lo contrario no funcionara. Esta funcionalidad no la tiene tu navegador de escritorio.
Al presionar el boton grande “Compartir” sale este cuadro de dialogo nativo de android:
¿Qué debes tomar en cuenta?
Esta funcionalidad solo se puede ejecutar con la accion del usuario, es decir, solo se puede invocar en controladores de eventos como click.
Solo se puede ejectar en Android y en el navegador web Chrome >= 61
En el ejemplo anterior, primero nos aseguramos que el navegador soporta la funcionalidad con navigator.share.
Cada patrón describe un problema que ocurre una y otra vez en nuestro entorno, y luego describe el núcleo de la solución a ese problema, de tal manera que puedes utilizar esta solución millones de veces, sin nunca hacerlo de la misma forma dos veces.
Arquitecto Christopher Alexander
La definición del patrón de diseño no viene del desarrollo de software, sino de la arquitectura del habitat humano.
Tanto la arquitectura del hábitat humano como el desarrollo de software tienen muchas similitudes, esto es porque como seres humanos somos parte del mundo y de la naturaleza. Por lo tanto el desarrollo de software busca siempre representar el mundo real, de hecho la programación de cualquier aplicación siempre se usa para solucionar problemas reales de nuestro entorno.
Entonces podemos comprender que un patrón de diseño permite ofrecer una solución a problemas comunes en el diseño de software, describe la solución a problemas que se repiten muchas veces y que son muy similares entre ellos, en concreto, esta similitud permite diseñar una solución para un conjunto de problemas parecidos.
Los patrones de diseño actuales fueron popularizados por el libro Design patterns: elements of reusable object-oriented softwarede los autores conocidos como GoF(Gang of Four):
Erich Gamma
Richard Helm
Ralph Johnson
John Vlissides
En este libro se describen 23 patrones de diseño que desde 1995 hasta nuestros días siguen en uso con un gran impacto en el desarrollo de software. Esto no quiere decir que estos patrones no fueron utilizados mucho antes de la publicación del libro.
Este artículo será el primero de una serie, que nos permitirá entender como se pueden implementar muchos de estos patrones de diseño en el lenguaje de programación Javascript y no solo los descritos por GoF, también se explicara otros patrones de diseño útiles en Javascript.
El primer patrón de diseño es el Patron Singleton.
Patrón Singleton
Este patrón nos permite tener una solo instancia de un tipo de objeto, porque no es necesario crear varias instancias nuevas cuando una solo instancia puede encargarse del mismo trabajo en toda la aplicación. Al solo tener una instancia, centralizamos la información, funcionalidad y mejoramos el rendimiento disminuyendo el uso de memoria.
En Javascript es muy fácil utilizar este patrón, tan fácil como crear un objeto literal, por ejemplo supongamos que tenemos una configuración para el número de caracteres y palabras que se muestran en un sitio web optimizado para buscadores:
let configSEO ={name:'Pensemosweb',seo:{descripcion:{limiteCaracteres:155,limitePalabras:23},titulo:{limiteCaracteres:70,limitePalabras:9}}};
Un simple objeto de configuración es un singleton, pues en toda la app se va a hacer referencia al objeto configSEO y nunca se va a crear más nuevos objetos porque se puede extender esa configuración añadiendo más propiedades.
Ahora supongamos que necesitamos utilizar objeto donde existan funciones de configuración y métodos, además de una interfaz para obtener la instancia, tomando el mismo ejemplo de configSEO ahora vamos a utilizar funciones anidadas y closure (o cierres), esto ultimo permite a una función tener acceso a las funciones y variables definidas en el ámbito en que esta función también es definida.
La función anónima principal se invoca inmediatamente con la notacion (function() {}()) y recibe un parámetro el, el cual guarda la referencia al elemento del DOM con id resultado. Este parámetro se lo pasamos a la función inmediata a través de la variable global elem.
Debido a que definimos instancia dentro de la función principal, las funciones anidadas definidas más adelante tienen acceso a esa variable instancia que guardara nuestro singleton cuando invoquemos la función configSEO().
Además metodoPublico()and privada() tienen acceso a las variables instancia and el.
Si nos fijamos en la línea 48, elem.append(conf1 === conf2), comparamos igualdad de referencia, conf1and conf2son el mismo objeto, como singleton, solo trabajamos con una instancia.
También podemos hacer uso de otro patrón de diseño llamado factory, el cual veremos más a detalle en otro post, por el momento solo ten en cuenta que tendremos una función que fabricara singletons.
Podemos notar que con una sola función, podemos acceder a los singletons creados anteriormente y podemos agregar más si queremos. Este tipo de patrón factory de singletons es muy utilizado en frameworks como AngularJS. Aquí abajo un ejemplo del singleton configSEO y el factor y usando AngularJS.
scheme, Paradigma funcional. Influenciado por Lisp
Self, Paradigma orientado a objetos, basado en prototipos en lugar de clases. Influenciado por Smalltalk
A mediados de los noventa, la compañía Netscape necesitaba un lenguaje para su navegador web. Entonces contrataron a Brendan Eich quien inicialmente quería usar algo como scheme dentro del navegador.
En esa época, Netscape tenía tratos con Sun microsystems para mostrar Java en el navegador a través de applets. Así que tenían en mente un lenguaje hermano, mucho más simple. Pero poquito despues sintieron que ya no deberían crear este lenguaje, que con Java era suficiente.
Al final gracias a Brendan y otras dos personas de Netscape y Sun Microsystems, se vio la necesidad de un lenguaje que pudiera correr directo en una página web. Y que pudiera ser utilizado por personas que no supieran lo que es un compilador.
Brendan Eich tomó la sintaxis de Java, el modelo funcional de scheme, y la programación orientado a objetos basada en prototipos de Self.
Aunque la sintaxis la toma de Java, esta sintaxis realmente viene de C/C++ de los cuales Java surgió.
Javascript: scheme, self y Java en uno
JavaScript fue creado a prisas y con mucha presión, en diez días Brendan Eich creó la primera versión, aun así la habilidad de Brendan en tomar los mejores aspectos de los lenguajes de programación Scheme, Self y C/C++ han hecho de JavaScript un lenguaje muy potente y expresivo.
En un inicio se llamó mocha, después LiveScript en su primer lanzamiento oficial en 1995 y tres meses después lo llamaron JavaScript. Este último nombre tiene muy poco que ver con el lenguaje, según se entiende, lo llamaron así por estrategia de mercadotecnia porque Netscape incrustaba Java en el navegador web.
Tiempo después Netscape anuncio una reunión con la organización de estándares Ecma International para dar paso a la estandarización de Javascript. Así la primera edición ECMA-262, fue aceptada por la asamblea general de Ecma en junio de 1997. Realmente el estándar del lenguaje se llama ECMAScript.
¿Dónde se usa Javascript?
Javascript es un lenguaje de programación muy flexible, multiparadigma, dinámico y con un gran potencial, es por eso que lo encontramos actualmente en diferentes áreas, por mencionar algunas:
Navegadores web como Firefox, Google Chrome, Opera, Safari.
Aplicaciones móviles, incrustados en la aplicación nativa mediante WebViews, o con herramientas como Cordova and Ionic
En Node.js para crear servidores http, ftp y cualquier tipo de tecnología de red de una forma escalable, otro ejemplo es ejecutar scripts en tu sistema operativo para automatizar tareas.
Programación de Robots e IoT (Internet de las cosas), por ejemplo Arduino and johnny-five.
¿Cómo se usa Javascript?
Javascript es un lenguaje compilado en el momento (Just-in-time compiled), el motor de JavaScript recorre linea por línea y así va traduciendo el código a lenguaje maquina para que la computadora lo pueda entender. En las primeras versiones de JavaScript se ocupaba un intérprete.
Como ya mencionamos, Javascript no solo se puede ejecutar en el navegador web, sino también del lado del servidor, como lo hace en node.js, a estos lugares donde javascript se puede ejecutar se les llama ambientes huésped. Estos ambientes tienen sus propias funcionalidades y APIs que no son parte del estándar de ECMAScript. Por ejemplo, en el navegador encontramos los objetos window and document, en node.js podemos encontrar los objetos http and fs.
Para aprender cualquier otro lenguaje, todos sabemos que necesitamos saber su gramática, es por eso que vamos a ver la definición de gramática sacada de Wikipedia:
La gramática es el estudio de las reglas y principios que gobiernan el uso de las lenguas y la organización de las palabras dentro de unas oraciones y otro tipo de constituyentes sintácticos.
Solo veremos la gramática básica para poder empezar a crear código. De tal manera que se combinen con ejemplos prácticos y en próximas publicaciones iremos aumentando nuestro entendimiento de la misma forma.
Variables
One of the most used elements are variables, las variables son cajitas con etiquetas, y tienen un espacio de memoria para guardar algún tipo de dato.
Las etiquetas de las cajitas deben cumplir ciertas reglas. Su nombre o identifier no puede iniciar con un número, deben iniciar con alguna letra (incluyendo _ y $), y además Javascript es sensible a mayúsculas y minúsculas.
There are two ways to declare a variable. One is using var and the other using let.
Es importante describir correctamente el contenido de las variables, porque así le facilitamos la vida a la siguiente persona que necesite leer y modificar nuestro código. Esta siguiente persona muy a menudo eres tú del futuro, y al menos que seas un robot, no podrás recordar cada detalle de tu código.
Del código anterior, presta atención solo a las definiciones de variables, ahí tanto let como var tienen el mismo efecto, definen una variable global que puede ser accedida en cualquier parte de la ejecución.
También podemos ver que no es necesario definir el tipo de dato, y realmente no lo necesitamos, vemos claramente que las variables contienen cadenas de caracteres (string), un string se declaran dentro de unas comillas simples o dobles.
A las variables que no le definimos algún valor, Javascript les asigna el valor undefined.
Además de las variables existe un tipo de cajita que no puede cambiar lo que guarda una vez definido su valor, por eso se llaman constantes.
Al tratar de reasignar un valor a una constante como en la cuarta línea del código, JavaScript mostrara un TypeError, indicando que no se puede reasignar un valor a una constante.
Javascript es un lenguaje débilmente tipeado, o sea, que no es necesario definir el tipo de dato. Pero no quiere decir que no tenga tipos, pues el tipo de dato es definido en tiempo de ejecución por Javascript, recordemos que Javascript es un lenguaje compilado en el momento.
Datos primitivos
Casi todo en JavaScript es un Objeto, la excepción son los datos primitivos, los cuales no son Objetos y no tiene métodos, entonces tenemos siete tipos de datos, objects y los siete primitive data de abajo:
number, números como; 1, 0, 18500, 89.95124
BigInt, agregado en el 2020, para representar números enteros muy, pero muy grandes.
String, cadena de caracteres como ‘Hola’ y ‘Buenas noches’.
Boolean, solo acepta true o false, es decir, si o no.
null, sirve para indicar que algo es nada, su único valor es null.
undefined, serves to indicate that something is not yet defined.
symbol, nuevo en el lenguaje a partir de EcmaScript 6, año 2015
Objects
Todo lo demás son objects, incluso los tipos de datos String, Boolean, Number y Symbol tiene su correspondiente representación en Objeto. Una función es un objeto. Ejemplos de objetos:
object
function
array
date
RegExp
Mistake
La verdad que no preocuparme por el tipo de dato me ha facilitado el desarrollo de software. Además los editores de código vienen con muchas herramientas y plug-ins que te ayudan mucho en este aspecto, te ahorras bastante dolor de cabeza al tratar de convertir entre tipos.
Solo nos interesa lo que nuestro objeto puede hacer, no de que tipo es o si es padre o hijo de algo. Cuando realizas una suma entre números en el mundo real, no te importa que tipo es, solo te importa que se puedan sumar, sin importar si es un entero o decimal, o fracción.
Normalmente si nombras tus variables/objetos de manera adecuada y de manera muy entendible, con el contexto de tu función, modulo o componente sabrás que tipo de datos son.
Su valor ya te indica de que tipo es, me parece redundante definir el tipo de algo a lo que yo mismo le asigno el valor.
Comentarios
Aunque los comentarios no los recomiendo porque son un indicador de que nuestro código no es fácil de entender, se pueden usar para casos en los que ya no tenemos de otra.
La sintaxis de los comentarios fue tomada de C++.
// Este es un comentario de mucho valor
/**
* Este es un comentario con mas de una linea
* y esta es la segun linea
* y una tercera linea
*/
Funciones
Las funciones son otro de los elementos más importantes del lenguaje. Si no es que el más importante. Con una función podemos realizar un conjunto de acciones sin volverlo a escribir y nos permitirá obtener un resultado según los argumentos que recibe a la hora de ejecutarla.
Pero no solo eso, nos permite resolver problemas desde el punto de vista de paradigmas de programación como funcional y orientado a objetos. Por poner un ejemplo, nos permite crear patrones de diseño muy útiles como el Singleton o el Patron de diseño Observador.
¿Por qué las funciones son tan flexibles en JavaScript? Porque las funciones son objetos de primera clase en el lenguaje. Es decir, pueden ser tratadas como cualquier otra variable, pueden ser pasadas como parámetros y pueden ser el valor de retorno de otra función.
Un consejo, selecciona bien tus nombres, un nombre de función debe ser un verbo, porque internamente realiza una acción.
Otro consejo procura usar muy pocos argumentos, no más de tres, créeme, no todos tenemos memoria de fotográfica y con muchos argumentos es difícil reusar la función. Porque no sabremos que parámetros recibe y en que orden.
Cuando queremos que el código de una función se ejecute, se dice que necesitamos invocar la función. Para invocar a una función se deben poner un par de paréntesis (), y si tiene parámetros o argumentos, estos se separan con comas.
En el ejemplo vemos como invocamos dos veces la función getNombreCompleto(nombre, apellido) ahorrando tiempo y esfuerzo obteniendo un resultado similar. Esta función recibe dos parámetros, los cuales separamos con una coma.
Ámbito de variables
En Javascript no existe ámbitos de bloques como en C y Java, donde las variables definidas en un bloque utilizando llaves {} solo existen en ese ámbito y no puede ser accedidas desde afuera.
JavaScript tiene ámbito de función, para ilustrar este tipo de ámbito vamos a crear una función donde se definen dos variables. Más adelante en el código, fuera de la función se intenta obtener el valor de la variable James, pero esto no es posible y tendremos un ReferenceError.
Hasta junio del 2015 solo existía la forma de var para declarar variables. Actualmente la forma let de declarar variables permite utilizar ámbito de bloque. Por ejemplo en un bloque if, o simplemente dentro de llaves:
Por último veamos como crear un objeto. Un objeto literal es una colección de pares nombre: valor, parecido a los arrays asociativos de PHP. Estos pares de nombre/valor se les llama propiedades, una propiedad es como una variable y puede contener cualquier tipo de valor.
Para crear un objeto no necesitas crear una clase, tú simplemente creas el objeto y lo empiezas a utilizar.
In the example we have an object person, has several properties of different types, its name is a String, his age is a number, getName and talk are of type function, functions that are members of an object are called methods.
Para poder entender la relación entre Javascript, scheme, self and java, tenemos que entender un poco de la historia de los lenguajes.
No somos creadores de la historia. Estamos hechos por la historia.
Martin Luther King, Jr.
De Algol a Smalltalk
Los lenguajes de programación más usados en los sesentas, eran:
FORTRAN
LISP (Paradigma funcional)
COBOL
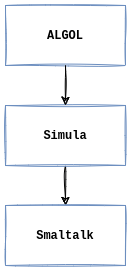
ALGOL
ALGOL (Algorithmic Language) introdujo la utilización de bloques utilizando las palabras reservadas begin and end.
Como clara influencia, actualmente en JavaScript, C, Java, entre otros, se utiliza las llaves {} para definir bloques de código.
En 1967 se lanzó Simulates 67, Simulates fue el primer lenguaje de programación orientado a objetos, básicamente le agregó clases y objetos a ALGOL.
La programación orientada a objetos fue descubierta en 1966 por los mismos creados de Simula, Ole Johan Dahl and Kristen Nygaard.
Some time later it was created Smalltalk, a much more sophisticated and modern object-oriented programming language, in charge of this project was Alan Kay.
Alan Kay commented:
I'm sorry I coined the term a long time ago. Objects for programming because it made people focus on the least important part. The big idea is “Sending messages“.
Alan Kay
Camino smalltalk
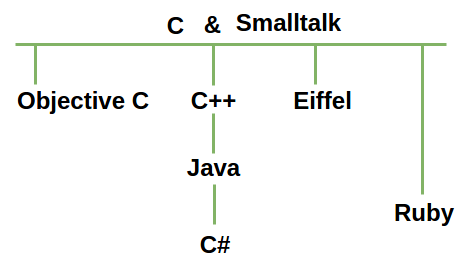
Posteriormente se empezaron a crear otros lenguajes de programación orientados a objetos, todos basados en ideas de Smalltalk and C.
Se crearon Objective C, C++ y Eiffel, de los cuales surgieron otros lenguajes de programación como Java, C# y Ruby.
Influencias sobre lenguajes de programación orientada a objetos
JavaScript surge poquito después de JAVA, en el mismo año. JavaScript tomará influencias de smalltalk, porque Self fue influido por smalltalk.
De Smalltalk a Self
Smalltalk It also allowed the creation of Self, creado en Xerox Parc y luego migrado a Sun Microsystems Labs.
In this programming language the idea of prototypes, eliminating the use of classes to create objects, this language uses the objects themselves to allow one object to reuse the functionalities of another.
Self It is a fast language and is generally known for its great performance, self hizo un buen trabajo en sistemas de recolección de basura y también utilizaba una maquinar virtual para administrar su ejecución y memoria.
La maquina virtual Java HotSpot se pudo crear gracias a Self, debido a la influencia de Self tenemos hoy en día el motor de JavaScriptV8, which uses it node.js yGoogle Chrome internally.
Self followed one of the book's recommendations Design Patterns: Elements of Reusable Object-Oriented Software, long before it came out, published this recommendation:
Better composition of objects to class inheritance.
Design Patterns: Elements of Reusable Object-Oriented Software
Actualmente Javascript utiliza prototipos para la reutilización de código, se podría decir que usa composición, en lugar de herencia.
De cálculo lambda a Scheme
Functional programming is the oldest programming paradigm, in fact its discovery was long before computer programming, it was discovered in 1936 by Alonzo Church, when I invented the lambda calculus mientras resolvía el mismo problema matemático que Alan Turing.
El símbolo del cálculo lambda es :
λ
LISP fue el primer lenguaje funcional, creado por John McCarthy.
JavaScript tomó influencias de LISP, porque scheme fue influido por LISP.
Smalltalk uses the “The Actor Model”, which says that actors communicate with each other through messages.
On the other hand we have LISP, which has a “Function dispatcher model” What we currently call functional language, these models are identical, because what functions and methods do is send messages between actors.
An example of this is when a function calls another function or when an object's method is invoked, what happens is that actors exist and they communicate with each other through messages.
Entonces podemos decir que la idea principal de la programación orientada a objetos es el envío de mensajes y que no es muy diferente de la programación funcional. Y aquí es importante remarcar lo que dijo Alan Kay Co-creator of SmallTalk:
I'm sorry I coined the term a long time ago. Objects for programming because it made people focus on the least important part. The big idea is “Sending messages“.
Alan Kay
Mi ingles es malo así que pueden revisar el texto original here.
Tomando estos dos modelos idénticos, se refinaron, y se creó scheme.
scheme has the goodness to use tail recursion and closure to obtain a functional language, closure permite tener acceso a las variables de una función externa aun cuando esta ya haya regresado algún valor.
Javascript usa mucho closure en su faceta de lenguaje funcional.
Predecesor de la PC moderna y el desarrollo de componentes web
On the other hand we have NLS (oN-Line System), fue un sistema de colaboración entre computadoras diseñado por Douglas Engelbart e implementado por la ARC (Augment Research Center) en el Instituto de investigación de Stanford SRI.
Fue el primer sistema en usar enlaces de hipertexto, mouse, monitores de video, Información organizada por relevancia, GUI (Interfaces gráficas de usuario), programa para presentaciones y otros conceptos modernos de computación.
Después cuando Steve Jobs se le ocurrió la idea de crear la computadora personal más sofisticada, la Macintosh (esta idea venía concebida desde NLS), los programadores tenían que usar lenguaje ensamblador para crear programas.
Era muy difícil conseguir programadores que desarrollaran en ensamblador, debido a esta dificultad, Bill Atkinson que ya había creado MacPaint and QuickDraw, se le ocurrió crear una interesante aplicación que le permitiera a personas que no se dedicaran a la programación crear fácilmente programas.
A esta aplicación le agregó un lenguaje de scripting, y se le llamó HyperCard, tenía botones, enlaces y muchas cosas que actualmente se tienen en el desarrollo web, en la web misma y en los navegadores modernos.
Hypercard
Por ejemplo para agregar un botón tú pulsabas Cmd + B y se abría un cuadro de diálogo para crear el botón y tenía las opciones de configuración que se ven en la imagen de abajo, poner icono, algún efecto y hasta agregarle funcionalidad a través de un script.
IDE HyperCard agregar un botón
Una gran ventaja de HyperCard es que si tú creabas un componente como un botón y te lo llevabas a otra tarjeta o página, el botón seguía teniendo toda la configuración, incluyendo el script.
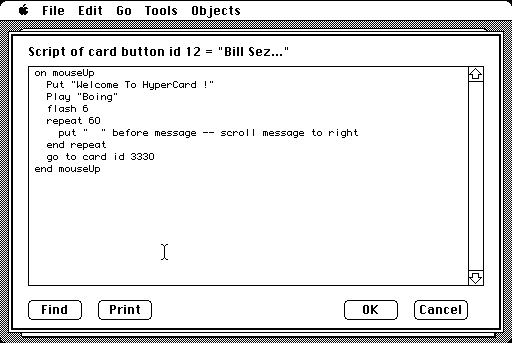
Es claro que esto ultimo es un predecesor de los componentes web actuales. Su lenguaje de script se llamaba HyperTalk y era así:
HyperTalk script parecido a Javascript
Se puede notar el parecido con la funcionalidad mouseup de los navegadores web actuales, de hecho el creador de JavaScript tomo esta influencia para agregar eventos a elementos de un sitio web, como por ejemplo el onmouseup:
Surgimiendo de los navegadores web
Se empezó un proyecto llamado Xanadu, este sistema computacional utilizaba el concepto de hipertexto.
La idea de Xanadu era el fin de concebir un documento global y único que cubra todo lo escrito en el mundo mediante una gran cantidad de ordenadores interconectados que contenga todo el conocimiento existente.
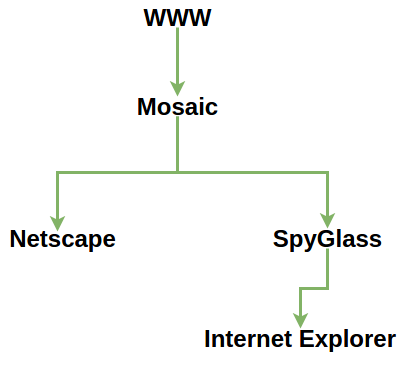
Xanadu fue el predecesor de WWW, tiempo despues Tim Berne’s Lee creó la WWW o World Wide web.
Con la WWW funcionando, vinieron los navegadores web como Mosaic, este se dividió en Netscape and SpyGlass.
Tiempo después SpyGlass fue comprado por Microsoft para poder concebir al navegador más odiado por los desarrolladores web, Internet Explorer.
Surgimiento de Internet Explorer y Netscape
De navegadores web a Javascript
A mediados de los noventa, la compañía Netscape necesitaba un lenguaje para su navegador web, así que contrataron a Brendan Eich quien inicialmente quería usar algo como scheme dentro del navegador.
Netscape tenía tratos con Sun microsystems para mostrar Java en el navegador a través de applets, así que tenían en mente un lenguaje hermano, mucho más simple. De hecho en un punto ya no sintieron que deberían crear Javascript, pensaban que con Java era suficiente.
Al final gracias a Brendan y otras dos personas de Netscape y Sun Microsystems, se vio la necesidad de un lenguaje que pudiera correr directo en una página web, que pudiera ser utilizado por personas que no supieran lo que es un compilador.
Brendan Eich tomó la sintaxis de Java, el modelo funcional de scheme, y la programación orientado a objetos basada en prototipos de Self.
Aunque la sintaxis la toma de Java, esta sintaxis realmente viene de C/C++ de los cuales Java surgió.
Javascript: scheme, self y Java en uno
Ahora bien si nos ponemos a pensar, Javascript tiene más que ver con LISP y Scheme en la parte funcional, con Self en la parte orientada a objetos y con C/C++ en su sintaxis.
JavaScript fue creado a prisas y con mucha presión, en diez días Brendan Eich creó la primera versión, aun así la habilidad de Brendan en tomar los mejores aspectos de los lenguajes de programación Scheme, Self y C/C++ han hecho de JavaScript un lenguaje muy potente y expresivo.
En un inicio se llamó mocha, después LiveScript en su primer lanzamiento oficial en 1995 y tres meses después lo llamaron JavaScript, este último nombre tiene muy poco que ver con el lenguaje, según se entiende, lo llamaron así por estrategia de mercadotecnia porque Netscape incrustaba Java en el navegador web.
Netscape anuncio una reunión con la organización de estándares Ecma International para dar paso a la estandarización de Javascript. Así la primera edición ECMA-262, fue aceptada por la asamblea general de Ecma en junio de 1997. Así que realmente el estándar del lenguaje se llama ECMAScript.
Javascript en múltiples plataformas
Javascript es un lenguaje de programación muy flexible, multiparadigma, dinámico y con un gran potencial, es por eso que lo encontramos actualmente en diferentes áreas, por mencionar algunas:
Navegadores web como Firefox, Google Chrome, Opera, Safari.
Aplicaciones móviles, incrustado en la aplicación nativa, un ejemplo es Cordova and Ionic
En Node.js para crear servidores http, ftp y cualquier tipo de tecnología de red de una forma escalable, otro ejemplo es ejecutar scripts en tu sistema operativo para automatizar tareas.
Programación de Robots e IoT (Internet de las cosas), por ejemplo Arduino and johnny-five.
Conclusion
La implementación interna de la programación orientado a objetos y funcional desde el inicio en JavaScript, han hecho que este lenguaje de programación tenga el éxito global de hoy en día. Permitiendo crear un código más eficiente y expresivo