Redux es un contenedor predecible del estado de aplicaciones JavaScript.
Te ayuda a escribir aplicaciones que se comportan de manera consistente, corren en distintos ambientes (cliente, servidor y nativo), y son fáciles de probar. Además de eso, provee una gran experiencia de desarrollo, gracias a edición en vivo combinado con un depurador sobre una línea de tiempo.
redux.org
Te permite controlar el flujo de datos de una aplicación Javascript, este flujo de los datos funciona en una sola dirección. Por esta única dirección es mucho más fácil controlar las mutaciones y operaciones asíncronas.
Redux es parecido a flux, de hecho está basado en flux
En el estado de una aplicación, principalmente en aplicaciones SPA, esto es muy importante, porque las aplicaciones web modernas tienen gran complejidad de operaciones asíncronas. Además de controlar el estado entre los componentes.
¿Qué problemas puedo mitigar con Redux?
En el ejemplo de aplicaciones web, estas necesitan controlar peticiones a servidores, obtener datos y controlar el estado en el cliente. Aun cuando estos datos no han sido guardados en el servidor.
Estas aplicaciones modernas requieren de un control complejo y por eso nuevos patrones de arquitectura como Redux y flux nacen para hacer el desarrollo más productivo.
Las mutaciones de objetos son difíciles de manejar y más a escalas medianas y grandes. Se comienza a perder el control de los datos, este flujo de datos generan comportamiento no deseados. Mala información desplegada al usuario y código que es muy difícil de mantener.
Sin contar cosas más elevadas como tu salud y causa de estrés por el esfuerzo en arreglar estas inconsistencias, te hace perder tiempo para mantener la aplicación funcionando correctamente. Por si fuera poco afectas a tus usuarios porque ellos obtienen información incorrecta y pierden su tiempo al utilizar esa información.
¿Qué decir de las operaciones asíncronas? Bueno, prácticamente pasa lo mismo o aún peor. Porque en una operación asíncrona no sabes cuando obtendrás el resultado y además normalmente vienen acompañadas con el deseo de hacer modificaciones al estado de la aplicación.
Un ejemplo común es el control de los datos de tu aplicación con cualquier frawework front-end de componentes visuales.
¿De qué está hecho Redux? Tres elementos
Store. El store es un objeto donde guardas toda la información del estado, es como el modelo de una aplicación, con la excepción que no lo puedes modificar directamente, es necesario disparar una acción para modificar el estado.
Actions. Son el medio por el cual indicas que quieres realizar una modificación en el estado, es un mensaje o notificación liviana. Solo enviando la información necesaria para realizar el cambio.
Reducers. Son las funciones que realizan el cambio en el estado o store, lo que hacen internamente es crear un nuevo estado con la información actualizada, de tal manera que los cambios se reflejan inmediatamente en la aplicación. Los reducers son funciones puras, es decir, sin efectos colaterales, no mutan el estado, sino que crean uno con información nueva.
¿Qué principios debo seguir? Tres principios
Un único Store para representar el estado de toda la aplicación. Tener una sola fuente de datos para toda tu aplicación permite tener centralizada la información, evita problemas de comunicación entre componentes para desplegar los datos, fácil de depurar y menos tiempo agregando funcionalidad o detectando errores.
Estado de solo lectura. Esto permite tener el control de cambios y evitar un relajo entre los diferentes componentes de tu aplicación, ni los componentes, ni peticiones ajax pueden modificar directamente el Estado (state) de tu aplicación, esto quiere decir que si quieres actualizar tu estado, debes hacerlo a través de actions, de esta manera redux se encarga de realizar las actualizaciones de manera estricta y en el orden que le corresponden.
Los cambios solo se hacen con funciones puras. Al realizar los cambios con funciones puras, lo que realmente se hace es crear un nuevo objeto con la información actualizada, estas funciones puras son los reducers y no mutan el estado, al no mutar el estado, se evitan problemas de control, datos incorrectos, mal comportamiento y errores, también permite que la depuración sea más fácil. Puedes dividir los reducer en varios archivos diferentes y las pruebas unitarias son fáciles de implementar. Los reducers son funciones puras que toman el estado anterior y una acción, y devuelven un nuevo estado.
Otras arquitecturas como MVC (Modelo, Vista, Controlador), los cambios pueden existir en ambas direcciones, es decir, la vista puede cambiar el estado, el modelo lo podría modificar y también el controlador. Todos estos cambios necesitan estar sincronizados en varias partes de una aplicación para evitar inconsistencias, lamentablemente este problema de inconsistencia se vuelve muy difícil y tedioso de resolver.
Lo anterior no sucede con Redux.
¿Cómo funciona? Mi primer estado predecible con Redux
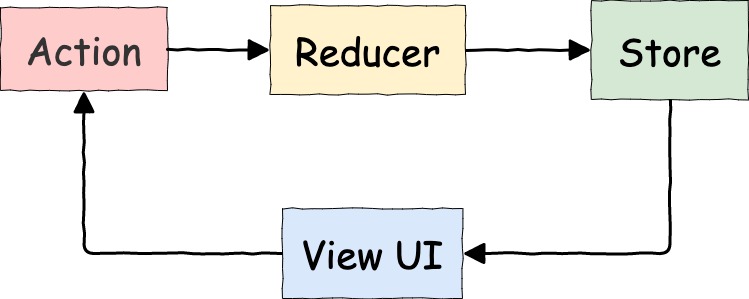
Primero veamos el flujo de una sola dirección de redux:
Redux: flujo de control una sola dirección
Ahora un ejemplo concreto para saber de que estamos hablando, el control de un contador:
Si quieres probar este ejemplo en tu máquina recuerda insertar o importar la librería Redux. En este ejemplo podemos ver el funcionamiento de Redux, cada vez que se da clic sobre los botones de incrementar y decrementar, el contador se incrementa y decrementa.
Si ahora nos vamos al código JS, podremos ver que solo tenemos una función llamada counter, esta función es un reducer y es una función pura, sin efectos colaterales.
Luego vemos que como parámetros recibe un state y un action, cuando creamos nuestro Store con Redux, estas funciones reducer son utilizadas para modificar el State.
Normalmente, el state, reducer y action son definidos en puntos diferentes, y pueden ser organizados en varios archivos y carpetas dependiendo de la necesidad de la aplicación, toda esta organización tiene la finalidad de tener un código limpio y separar funcionalidades. En este caso sencillo no es necesario, en un solo archivo tenemos todo.
State
Nuestro state es solo un valor numérico, el cual se va a incrementar o decrementar con los botones que están en la página, normalmente el state es un objeto literal o un array literal, pero en nuestro caso solo necesitamos un número. Su definición podría estar en otro archivo, sin embargo, para este ejemplo no es necesario, lo agregamos como valor por defecto del parámetro state.
functioncounter(state=0,action){...
Actions
Si seguimos revisando nuestro código, veremos unos cuantas condiciones que revisa el valor del parámetro action y dependiendo de la acción, se ejecuta alguna operación, en nuestro caso son las operaciones INCREMENTAR o DECREMENTAR.
Los actions no son más que objetos literales como los siguientes:
Los reducer revisan esos actions, en nuestro ejemplo:
if (action.type ==='INCREMENTAR') {returnstate+1;}if (action.type ==='DECREMENTAR') {returnstate-1;}
Con todo esto ya tenemos nuestro State y su estado inicial en caso de no estar definido, también nuestra primer reducer, counter, y nuestros primeros actions INCREMENTAR y DECREMENTAR.
Store
Es el momento de crear nuestro Store, utilizando la librería redux esto es muy fácil:
const store = Redux.createStore(counter);
Con la anterior línea, Redux crea un Store para controlar el estado de nuestra aplicación. Internamente, un Store es un Patrón observador que utiliza un Singleton para el State y expone los siguientes métodos principales:
store.getState()
store.subscribe(listener)
store.dispatch(action)
store.getState() te permite obtener el estado actual de tu aplicación.
store.subscribe(listener) ejecuta la función listener (u observador), cada vez que el store es actualizado.
store.dispatch(action) pide actualizar el estado, esta modificación no es directa, siempre se realiza a través de un action y se ejecuta con un reducer.
Reaccionar a cambios del state
Luego creamos una función render, para que se ejecute cada vez que el State de tu aplicación cambie.
Aquí te preguntarás, ¿Cómo es posible que esa línea imprima 0 en la pantalla?, pues internamente el store invoca un dispatch con un action vacío store.dispatch({}), esto invoca nuestra función reducer y al no encontrar ninguna acción, entonces regresa el estado inicial 0.
Luego nos subscribimos a store para escuchar u observar el State cada vez que se actualice y poder ejecutar la función render().
store.subscribe(render);
Esta línea permite que cuando demos clic en los botones de incrementar y decrementar, se imprima el nuevo valor en la página volviendo a renderizar su contenido.
Ejecutar dispatch a través de eventos del DOM
Y por último agregamos dos listeners correspondientes a los botones de incrementar y decrementar, cada botón realiza una invocación dispatch para modificar el estado.
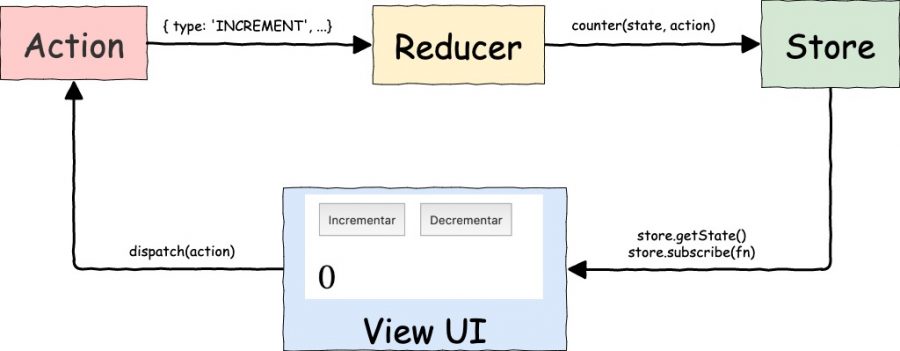
Al fin tenemos el flujo de datos de nuestro sencillo ejemplo usando Redux, en general los componentes que forman a una aplicación que utiliza Redux son los siguientes:
Redux: flujo de control completo
Conclusiones
Podemos notar el flujo en una sola dirección desde la vista con los actions dispatch(action), luego los reducers counter(prevState, action) para modificar el store y este último manda la información a través de subscribe(render) y getState().
Redux como ya se mencionó en párrafos anteriores, nos proporciona:
El conocimiento en todo momento del estado de nuestra aplicación y en cualquier parte de la aplicación con mucha facilidad.
Fácil organización, con actions, reducer y store, haciendo cambios en una sola dirección, además puedes separar tus actions, reducer y el store en varios archivos.
Fácil de mantener, debido a su organización y su único store, mantener su funcionamiento y agregar nuevas funcionalidades es muy sencillo.
Tiene muy buena documentación, su comunidad es grande y tiene su propia herramienta para debuguear
Todos los puntos anteriores hacen que sea fácil de hacer pruebas unitarias.
Y lo más importante, te ahorra tiempo, dinero y esfuerzo xD.
Antes de todo, estoy en el proceso de aprendizaje de React y en esta publicación voy a explicar, según mi entendimiento, los métodos del ciclo de vida de un componente con React.
A partir de la versión 16.3 de React se agregaron nuevos métodos del ciclo de vida de un componente para mejorar el rendimiento, buenas practicas y así obtener una mejor calidad de los componentes creados.
Principalmente este cambio es debido a componentes con funcionalidad asíncrona, esto es muy importante porque normalmente el mundo real es asíncrono y los componentes que creamos son utilizados en el mundo real por personas.
Por esta razón también se empiezan a dejar de utilizar los siguientes métodos, esto sucederá a partir de la versión 17 de React:
componentWillMount()
componentWillRecieveProps(nextProps)
componentWillUpdate(nextProps, nextState)
Dado que los anteriores métodos se dejaran de usar en la version 17, los siguientes métodos son los recomendados a utilizar en un componente:
Y para visualizar su relación, aquí está un diagrama de flujo:
Diagrama de los métodos del ciclo de vida de un componente en React
Si observamos el diagrama, el método static getDerivedStateFromProps(nextProps, prevState) sustituye al método deprecado componentWillReceiveProps(nextProps), también parece ser que el método getSnapshotBeforeUpdate(prevProps, prevState) sustituye al método deprecado componentWillUpdate(nextProps, nextState).
Para fines de demostración vamos a crear un componente Padre y otro componente Animal (componente hijo), lo ideal es que el componente Padre maneje todo el state, pero para demostrar el funcionamiento de los métodos ocuparemos algo de state en nuestro componente Animal.
constructor(props)
El constructor es un método de la mayoría de los lenguajes de programación orientada a objetos, y se utiliza para crear la instancia de una clase. En react el constructor se usa para crear la instancia de nuestro componente.
Cabe mencionar que después de la ejecución de este método, nuestro componente aún no se pinta en nuestro navegador, al proceso de pintado, es decir, insertarlo en el DOM, se le llama Montar o Mount en ingles.
Como buena practica de programación es importante ejecutar super() dentro de un constructor para que realice cualquier llamada a constructores padres.
En el caso de react se debe llamar con las props recibidas en el constructor, o sea, super(props), esto nos permite poder acceder a las props a través de this.props dentro del constructor.
El constructor se usa normalmente para las siguietes dos cosas:
Definir el estado local con un componente a través de this.state.
Para enlazar el objeto this(la instancia de nuestro componente) a los métodos que son utilizados en el método render(). Estos métodos son usados como manejadores de eventos
El estado de nuestro componente en el constructor se define así:
Si no defines ningún estado en el constructor, entonces no lo necesitas.
Si se te ocurre definir el state usando las props pasados como parámetros probablemente es mejor definir el state en un componente padre o en la raíz de todos los componentes porque el estado no estará sincronizado con los cambios de las propiedades.
Para enlazar la referencia de la instancia de nuestro componente a los métodos que son utilizados en el método render() y que normalmente son los manejadores de eventos:
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}this.cambiarAnimal=this.cambiarAnimal.bind(this);}cambiarAnimal(){this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Ahora el método this.cambiarAnimal podrá acceder a la instancia de nuestro componente a través de this y así utilizar this.setState() para cambiar el estado.
Existe otra opción para utilizar métodos de nuestra clase como manejadores de eventos, con el uso de funciones flecha (arrow functions).
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}}cambiarAnimal=()=>{this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Este método es estático, sí, debe tener el modificador static que indica que este método no está enlazado a alguna instancia del componente, sino más bien a su clase. Se invoca después de instanciar un componente y también cuando el componente recibe cambios en las propiedades.
Debe tener siempre un valor de retorno, ya sea un objeto para actualizar el state o null si no se quiere actualizar el state en relación con los nuevos valores de las props recibidas. Es importante saber que este método se ejecuta también cuando un componente padre provoca que el componente hijo sea de nuevo renderizado, por esta razón debes comparar valores anteriores con los nuevos para evitar mandar a actualizar el state cuando no hubo realmente un cambio.
Podemos razonar que este método nos puede servir para mantener sincronizado nuestro state (o solo una parte) con las props pasadas desde un componente padre.
Por el momento en nuestro ejemplo del componente Animal solo visualizaremos los datos y regresaremos null porque no queremos actualizar el estado, además el atributo src de nuestra imagen se actualiza cuando la propiedad src del componente cambia.
Lo siguiente realmente no es necesario, pero para visualizar la ejecución de este método supongamos que dentro de nuestro componente Animal vamos a manejar la url(src) de la imagen del animal en this.state.src, así:
constructor (props) {this.state={ src:props.src};}static getDerivedStateFromProps (nextProps, prevState) {if (prevState.src!==nextProps.src) {// necesario para actualizar la imagen cada vez que cambie this.props.srcreturn{ src:nextProps.src};}returnnull;}render() {return (<imgclassName="cat__img"src={this.state.src} /> );}...
Ahora prueba el código aquí, y revisa los mensajes de la consola, por el momento solo nos estamos enfocando en el constructor(props) y static getDerivedStateFromProps(nextProps, prevState):
render()
Este método es obligatorio en cualquier componente, pues como su nombre lo dice, se utiliza para obtener los elementos finales a visualizar o pintar en el navegador. Debe ser una función pura, es decir, no debe modificar las props, no debe modificar el state ni realizar operaciones del DOM.
Según mi entendimiento, el resultado de este método es utilizado por ReactDOM.render() para insertarlo en el DOM del navegador. Si el componente en cuestión ha sido insertado previamente, solo se muta el DOM lo necesario para reflejar los nuevos cambios, esto quiere decir querender() regresa los objetos necesarios para que en otro lugar sean insertados en el DOM.
Esto se puede comprobar si observas la consola del anterior ejemplo y luego das clic sobre el botón “Cambiar animal” entonces verás que el método render() es ejecutado antes de getSnapshotBeforeUpdate() y componentDidUpdate().
Con esto tengo una duda, ¿En qué momento se modifica el DOM?, yo creo que se modifica el DOM después deReactDOM.render()y antes de quecomponentDidUpdate().
Este método se ejecuta cuando nuestro componente está listo en el DOM, siguiendo el razonamiento explicado en el método render(), se ejecuta después de que React inserte el DOM, y antes del método `render()`. Por eso es útil para realizar llamadas ajax y operaciones con el DOM como agregar eventos y/o modificar elementos internos.
Dentro de este método es seguro cambiar el state, pero si ejecutamos this.setState() provocara que nuestro componente se vuelva a renderizar.
La documentación oficial de React nos advierte tener cuidado con esto, pues puede causar problemas de rendimiento por renderizar nuestro componente varias veces. Sin embargo es necesario para los casos de tomar medidas y posiciones de algunos elementos antes de renderizar, por ejemplo el tamaño y posición de modales y tooltips.
Para ver el uso de este método veamos el siguiente ejemplo, si revisamos la consola veremos que render() se ejecuta dos veces, también si damos clic en el botón Cambiar animal, se nota que de nuevo render() se ejecuta dos veces.
¿Por qué sucede esto?, sucede porque dentro del método componentDidMount() agregamos un escuchador de eventos para la carga de la imagen del animal, al ejecutarse this.onImgLoad().
`this.onImgLoad()` invoca a this.setState() y esta función provoca que el componente se vuelva a renderizar para mostrar las medidas exactas de la imagen cuando se termina de cargar.
shouldComponentUpdate(nextProps, nextState)
En versiones actuales de React, este método se ejecuta para decidir si los cambios en las props o el state merecen que se vuelva a renderizar el componente con estos nuevos datos.
El valor de retorno de esta función es true o false. Si el resultado de este método es true, los métodos render(), getSnapshotBeforeUpdate() y componentDidMount()no se ejecutan.
Recibe como parámetros las nuevos valores pros y del state, con estos valores y los valores actuales de nuestro componente podemos condicionar si es necesario volver a renderizar o no, de esta manera podemos mejorar el rendimiento manualmente.
Si no implementamos este método en nuestro componente, React toma como resultado el valor true, por lo que siempre se volverá a renderizar. El resultado no influye en los componentes hijos, si en un componente padre el resultado es false, esto no impide que componentes hijos necesiten volver a ser renderizados.
Es importante mencionar que en la documentación indica que tal vez en futuras versiones de React, este método no impida un renderizado del componente, o sea, que en un futuro si este método regresa falseaun así se ejecutaran los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
Esto último me deja con un sabor amargo, actualmente este método es un buen lugar para mejorar el rendimiento de nuestro componente porque evitamos el re-renderizado en situaciones que no sean necesarias, pero después en futuras versiones cabe la posibilidad de perder esta habilidad, entonces quiero pensar que deben existir otras maneras de mejorar este caso de rendimiento, ¿Alguien tiene alguna idea?.
Veamos un ejemplo, en el anterior método componentDidMount() mencionamos que agregamos un escuchador de eventos al finalizar la carga de la imagen para poder obtener sus medidas, estás medidas las mostramos en nuestro componente, pero esta el caso de dos imágenes de perros que tiene la misma medida, 128px - 128px, entonces el ancho y el alto de la imagen no cambia, por lo que no es necesario volver a renderizar nuestro componente.
Si cambiamos de entre el perro de raza chihuahua y el perro ladrando, podemos ver en la consola que el último método ejecutado es el shouldComponentUpdate(), como el resultado fue false, no se ejecutaron de nuevo los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
getSnapshotBeforeUpdate(prevProps, prevState)
Este método se ejecuta después de render() y antes de componentDidUpdate(), el valor que regresa la ejecución de este método se convierte en el tercer parámetro llamado snapshot de componentDidUpdate(prevProps, prevState, snapshot), este método debe regresar algún valor o null, si no es así, React nos advertirá con algo parecido al siguiente warning en la consola:
Warning:Animal.getSnapshotBeforeUpdate(): A snapshot value (or null) must be returned. You have returned undefined.
Además recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Este método puede regresar cualquier tipo de valor, por ejemplo puede regresar datos del DOM como cuantos elementos existen en una determinada lista de elementos o la posición del scroll antes de que el componente sea actualizado a través de ReactDOM.render()(si nuestra hipótesis explicada en el método render() es correcta).
Si revisamos el código de getSnapshotBeforeUpdate() y componentDidUpdate() y además revisamos la consola, notaremos que getSnapshotBeforeUpdate() le envía a componentDidUpdate el numero de elementos del DOM que contiene el componente en cuestión, que son 2, el párrafo con las medidas de la imagen y la imagen del animal.
Este método se ejecuta cuando el componente ha sido actualizado totalmente, y es reflejado en el DOM de nuestra aplicación, recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Aquí se puede trabajar con el DOM del componente dado que este mismo ha sido actualizado, además se puede realizar operaciones como obtener datos remotos según los cambios de las props o state.
No se ejecuta la primera vez que se usa el método render(), es decir, cuando se monta el componente.
En la consola podemos ver los datos, prevProps, preState, y snapshot, este último tiene el valor 2. También vemos this.props y this.state
componentWillUnmount()
Este método se ejecuta justo antes del que el componente sea desmontado del DOM, es un buen lugar para liberar recursos y memoria. Un ejemplo claro es la eliminación de escuchadores de eventos que ya no se van a necesitar, también se pueden cancelar peticiones remotas que se estén ejecutando actualmente dado que estas seguirán su proceso aún desmontando el componente.
En el ejemplo de abajo se ilustra como se elimina un escuchador de evento load para la carga de la imagen del animal.
El origen de la programación funcional data del año 1936, cuando un matemático llamado Alonzo Church necesitaba resolver un problema complejo, del cual no hablaremos aquí, pero Alonzo creó una solución, el cálculo lambda. De esta forma nació la programación funcional, incluso mucho antes de la primera computadora digital programable y de los primeros programas escritos en ensamblador.
La programación funcional es mucho más antigua que la programación estructurada y la programación orientada a objetos. Te recomiendo también revisar esta información sobre el paradigma de programación funcional.
Sin efectos colaterales
Todo lo que necesitas saber sobre programación funcional es que “No tiene efectos colaterales“, es decir, que sus elementos (funciones) son inmutables.
Lo anterior significa que una función no se mete en lo absoluto con datos que existen fuera de ella, si puede utilizar los datos enviados como parámetros, pero no debe modificarlos, todos los datos deben ser inmutables, ¿Por qué?, pues porque así hacemos las cosas más simples y con menos errores, más adelante tenemos un ejemplo. A este comportamiento se le llama puro.
Sin efectos colaterales nos permite entender todas las demás características de la programación funcional, por mencionar algunas principales:
Funciones puras
Inmutabilidad
Funciones de alto nivel
Funciones currificadas
Recursividad
Menos errores de programación porque no realiza efectos colaterales.
Toda función teniendo ciertos parámetros, cuando se ejecuta, obtendremos un resultado basado en esos parámetros, y si volvemos a utilizar los mismos parametros, entonces la función regresara el mismo valor. Esto es debido a que una función no depende de más datos externos que puedan ser modificados, así tendremos más seguridad y nuestro código se vuelve más entendible.
Bueno, realmente ya explicamos de manera indirecta que es una función pura en los párrafos anteriores, pero veamos una definición formal. Una función pura es la que cumple con estas dos características:
Siempre obtendremos el mismo resultado dado los mismos parámetros de entrada.
No tiene ningún efecto colateral observable, no modifica el estado de los datos externos, por lo que todos los datos deben ser inmutables.
Un ejemplo de como cambiar el nombre de una objeto persona usando primero una función con efector colaterales:
En la anterior función notamos que se cambia objeto jaime, el cual supongamos que es parte del estado de nuestra aplicación, pero puede haber otras funciones que utilicen este objeto, por lo que se puede generar problemas si alguien más espera que la propiedad nombre del objeto siga siendo 'jaime'.
En la versión funcional, cambiarNombre no modifica el objeto jaime, más bien crea un nuevo objeto con la misma edad que jaime y con la propiedad nombre igual a 'Juan', con esto evitamos efectos colaterales por si el objeto jaime es utilizado por otra función u otro programador.
Con esta función sin efecto colateral, nos damos cuenta de que los datos se manejan sin ser modificados, es decir, inmutables, los parámetros persona y nombre nunca fueron cambiados.
Funciones de alto nivel y currificadas
Una función de alto nivel es una función que implementa al menos una de las opciones siguientes:
Recibir como parámetro una o más funciones
Regresar como resultado una función
Un ejemplo muy común usado en nuestro navegador web es agregar escuchadores de eventos:
<buttonid="boton">Soy un botón</button>const boton = document.querySelector('#boton');boton.addEventListener('click',function(){alert('Click sobre el boton');});
En el código pasamos como segundo parámetro del método addEventListener unafunción anónima (sin nombre) que mostrará un alerta al dar click sobre un botón con id igual a ‘botón’. Dado que pasamos por parámetro una función, entonces se dice que es una función de alto nivel.
Otro ejemplo de función de alto nivel lo podemos observar en los métodos de arreglos en Javascript, el código de abajo toma un arreglo de números y crea otro arreglo con los valores aumentados al doble.
La función map retorna un nuevo arreglo, no cambia el arreglo original, por lo que decimos que no existe un efecto colateral.
Las funciones currificadas son funciones de alto nivel que como resultado regresan otra función, de tal manera que el acto de currificar es convertir una función de más de un parámetro en dos o más funciones que reciben parcialmente esos parámetros en dos o más invocaciones currificadas.
Las funciones flecha o arrow functions nos permiten acceder al contexto de los parámetros, es por eso que seguimos teniendo acceso al parámetro a de la primera invocación de summaryCurry. De esta manera cuando se les define un valor, una arrow function puede ver ese valor. Para lograr lo mismo sin funciones flecha se debe utilizar la variable argumentsque existe como variable local dentro de todas las funciones en JavaScript. Para mantener las cosas simples, de momento no veremos como hacerlo con arguments.
Función recursiva
Para crear una función recursiva, primero se define un caso base, luego a través de la división del problema en pedazos más pequeños se encuentra un patrón, este patrón llamado caso recursivo se repite muchas veces, es aquí donde la función se llama así misma y acumula los resultados, la ejecución se detiene hasta llegar a su caso base.
El caso base, el cual permite detener la ejecución de subsecuentes invocaciones de la función recursiva.
El caso recursivo, el cual permite que una función se llame a sí misma hasta llegar al caso base.
El factorial de un número positivo es la multiplicación de ese número por el número inmediato menor y así sucesivamente hasta llegar al número 1, su notación es n!, donde n es un número positivo. Por ejemplo el factorial de 5 es 120, 5! = 5 x 4 x 3 x 2 x 1 = 120.
// caso base:1!=1=1// caso recursivo, ejemplos:2!=2 x 1=2 x 1!3!=3 x 2 x 1=3 x 2!4!=4 x 3 x 2 x 1=4 x 3!5!=5 x 4 x 3 x 2 x 1=5 x 4!
Con estos datos, podemos crear nuestra formula factorial(n) = n * factorial(n-1), lo cual seria nuestro caso recursivo, pero debemos de añadir nuestro caso base para que se detenga, cuando n=1 debemos obtener como resultado 1.
Veamos como quedaría nuestra función recursiva en javascript:
El patrón de diseño observador, define una dependencia de uno a muchos objetos de tal manera que cuando un objeto cambio de estado, todos sus dependientes son notificados y actualizados automáticamente
Del libro “Design patterns: elements of reusable object-oriented software”
Si has utilizado eventos del navegador, como escuchar el evento click sobre un botón, ahí estás utilizando el patrón observador, tu función callback es tu objeto observador y el botón es el sujeto, tu función callback esta interesada en la actividad de dar click sobre el botón.
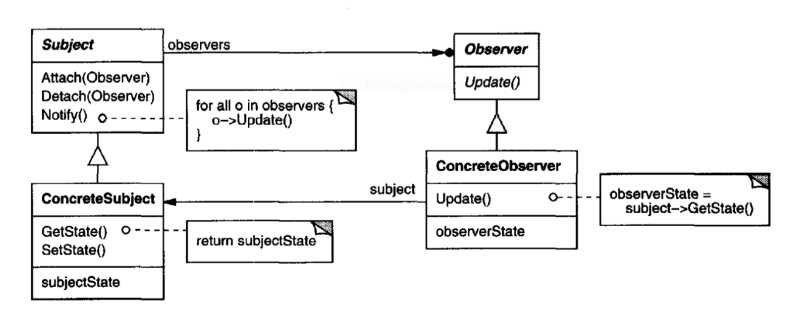
El Sujeto está compuesto por las siguientes métodos importantes que usaremos en nuestro código javascript:
Una colección de observers
Método attach()
Método detach()
Método notify()
Normalmente un Observador contiene un método update() que el Sujeto utiliza.
Para tener más claro esto, vamos a ver dos ejemplos del patrón observador, el primero será el Observador puro y el segundo en su modo Publicador/Suscriptor.
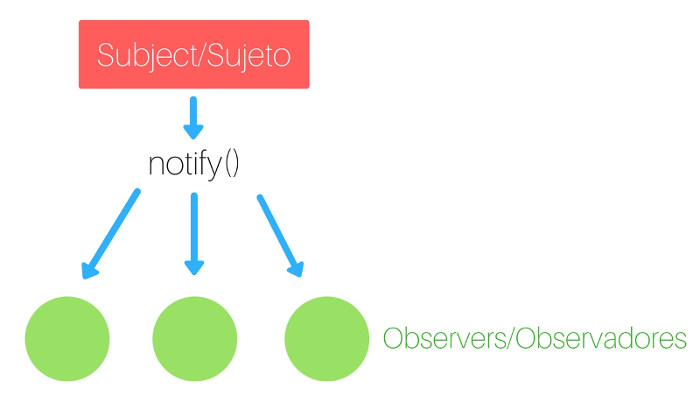
Simplificando el observador
Simplificando el diagrama anterior, el patrón observador funciona así:
Patrón de diseño observador simplificado
Juega con el ejemplo de abajo, y agrega nuevos checkbox, si has agregado más de un nuevo checkbox, podemos notar que cuando damos click en el checkbox ‘Seleccionar‘ todos los demás checkbox nuevos se enteran de esa actividad y se actualizan automáticamente.
Todo esto sin necesidad de estar al pendiente de que el checkbox ‘seleccionar‘ ha cambiado su estado, el encargado de notificar del cambio es el Sujeto y solo si existe algún cambio. Esto es muy eficiente si tienes cientos o miles de checkbox observando ese cambio.
Si das click sobre uno de los checkbox, se ejecuta el método subject.detach(), entonces ese checkbox ya no es un observador, por lo que si ahora activas y desactivas el checkbox seleccionar nunca es notificado sobre el cambio.
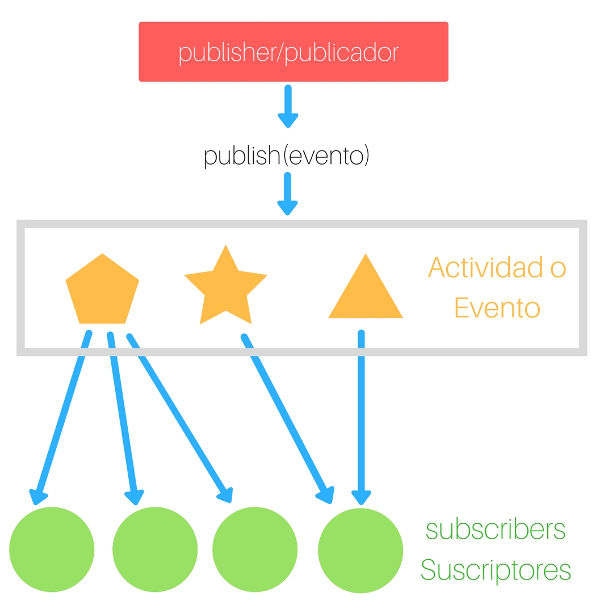
Publicador/suscriptor simple
El patrón de diseño publicador/suscriptor es una variación del observador, en este modo el suscriptor u observador se suscribe a una actividad o evento del publicador o sujeto.
El publicador notifica a todos los objetos suscritos cuando el evento al que están interesados se dispara o publica.
El publicador está compuesto por las siguientes métodos importantes que usaremos en nuestro código javascript:
Una colección de observers o subscribers
Método subscribe() o attach()
Método unsubscribe() o detach()
Método publish() o notify()
Aquí dejo el diagrama simple de como funciona esta versión:
Patrón de diseño publicador/suscriptor simplificado
El publicador/suscriptor se parece más a los eventos del DOM y a eventos personalizados, pero no deja de ser el patrón de diseño Observador. Ademas, como observadores, podemos suscribirnos a más de una actividad o evento.
En el ejemplo, el método suscribe agrega la función observadora, esta última se ejecuta cuando la actividad click es publicada.
En conclusión, el patrón de diseño observador es muy útil, se puede modificar o adecuarlo a ciertas necesidades, un ejemplo es la variacion publicador/suscriptor. Se usa en:
ReactveX.
Librerias y frameworks de componentes web tales como angular, react, lit, vue, svelte utilizan este patrón para su bindeo de datos.
Navegadores web cuando usamos eventos
Node.js cuando utilizamos EventEmitter al recibir una petición a nuestro servidor o al leer un archivo del disco duro.
Flux y redux para manejar cambios en el estado de nuestra aplicación.
Para crear un servidor web en node.js, primero, ¿Qué es node.js?, tomando la definición del sitio oficial, Node.js®es un entorno de ejecución para JavaScript construido con el motor de JavaScript V8 de Chrome. Node.js usa un modelo de operaciones E/S sin bloqueo y orientado a eventos, que lo hace liviano y eficiente. El ecosistema de paquetes de Node.js, npm, es el ecosistema más grande de librerías de código abierto en el mundo.
Vamos a describir la parte que nos interesa, Node.js es un programa, V8 es un motor de javascript de código abierto creado por Google, por lo que también lo hace un programa, V8 está escrito en C++, y la tarea de V8 es tomar código Javascript y convertirlo a código máquina (compilar código), pero lo que lo hace especial para nuestros fines es que puede ser embebido dentro de otros programas, lo que permite que V8 esté embebido en Node.js, V8 por así decirlo es el punto de partida para toda la funcionalidad de Node.js.
Node.js también está escrito en C++ y utiliza la API de V8 para agregarle características y funcionalidades nuevas a Javascript. Estas nuevas funcionalidades permiten tener acceso al sistema de archivos y carpetas, nos permite crear un servidor TCP y http, además de acceso a POSIX, o sea, a toda la funcionalidad del sistema operativo donde se encuentre instalado.
Node.js proporciona la sintaxis Javascript para crear programas que tengan acceso a las características del sistema operativo donde sé está ejecutando.
Con esto podemos razonar que con Node.js podemos crear un servidor web, para crearlo, vamos a utilizar NPM (Node Package Manager) y express.js un frawework web.
Vamos a crear una nueva carpeta llamada mi-servidor-web, luego accede a esta carpeta con:
$ cd mi-servidor-web
Ahora vamos a iniciar el proyecto utilizando el siguiente comando:
$ npm init
La línea de comandos nos pedirá algunos datos, puedes dar “enter” a todos si quieres, te muestro un ejemplo:
Press ^C at any time to quit.packagename: (mi-servidor-web)version: (1.0.0)description: Mi primer servidor webentry point: (index.js)test command:git repository:keywords:author: Jaime Cervantes<jaime.cervantes.ve@gmail.com>license: (ISC)About to write to /home/jaime/develop/node.js/mi-servidor-web/package.json:{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC"}Is this ok? (yes)
npm init nos genera un archivo package.json:
{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC"}
Este archivo contiene la información anteriormente proporcionada y además se encarga de controlar los paquetes que instalamos para nuestro proyecto. Por ejemplo, para poder crear nuestro servidor rápidamente, vamos a instalar un paquete llamado express.js de la siguiente manera:
$ npm install express --save
Este comando instala express.js y además actualiza nuestro archivo package.json gracias al parámetro --save en la propiedad dependencies:
{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC","dependencies": {"express":"^4.16.2"}}
Ya teniendo express instalado, vamos a crear nuestro servidor web creando el archivo ./mi-servidor-web/index.js:
const express =require('express');const app =express();app.use(express.static(__dirname +'/public/'));app.listen('3000',function(){console.log('Servidor web escuchando en el puerto 3000');});
Hay una parte importante que nos permitirá ver el funcionamiento de nuestro servidor web:
app.use(express.static(__dirname +'/public/'));
Esta línea le indica a nuestro servidor que cuando un usuario haga una petición de archivos estáticos, por ejemplo, http://localhost:300/index.html enviará como respuesta el contenido de ./public/index.html.
Vamos a crear la carpeta public y el archivo index.html con el editor de nuestro preferencia o en línea de comandos si lo deseas. Agregamos el siguiente contenido a nuestro archivo index.html:
<!DOCTYPE html><htmllang="es"><head><metacharset="UTF-8"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Mi primer servidor web</title></head><body><h1>HOLA, mi primer servidor web</h1></body></html>
Para ejecutar nuestro servidor nos posicionamos dentro de nuestra carpeta mi-servidor-web y ejecutamos el siguiente comando:
$ node index.js;
Veremos este mensaje en nuestra consola:
Servidor web escuchando en el puerto 3000
Por último abrimos nuestro navegador web y obtendremos nuestro index.html como la imagen de abajo, utilizando http://localhost:3000 o http://localhost:3000/index.html:
En Javascript se utiliza mucho los Patrones Glob, estos permiten seleccionar un número de archivos con una sintaxis parecida a las expresiones regulares pero con menos caracteres comodín y menor complejidad. Un carácter comodín es él * o el signo de ?.
Una gran diferencia entre expresiones regulares es que los patrones glob se ocupan para buscar y filtrar archivos, y las expresiones regulares funcionan con cadenas de texto.
Expresiones regulares trabaja con Texto
Glob trabaja con archivos/directorios
¿Origen?
Tienen su origen en las primeras versiones de Unix, durante la versión 6 para ser exacto, 1969-1975, era el programa /etc/glob, se usaba para seleccionar un conjunto de archivos en la shell, se llamaba glob por ser la abreviación de global.
¿Cómo se usan?
También la funcionalidad es un poco diferente, por ejemplo el * en una expresión regular coincide con la ausencia o cualquier número de repeticiones del carácterque le precede.
Por ejemplo a*, indica cero o más repeticiones de la letra a.
Otro ejemplo con carácter especial es .* el cual indica cero o más repeticiones de cualquier carácter, excepto carácter de nueva de línea.
Por otro lado el carácter * en un patrón glob representa la ausencia o cualquier número de repeticiones de cualquier carácter.
El ejemplo más utilizado es cuando queremos listar archivos con una determinada extensión, por ejemplo:
/$ ls *.js
Muy similar con lo que hacemos en el MS-DOS de windows:
C:\> dir *.js
No es necesario un carácter antes del *, como sucede con las expresiones regulares.
Aquí abajo un ejemplo donde tenemos un archivo de configuración de jasmine, Jasmine es un framework para realizar pruebas a tu código Javascript, este archivo de configuración permite seleccionar que archivos se usarán para ejecutar las pruebas:
Algo que destacar es el uso de doble asterisco **, esto indica cero o más coincidencias de cualquier subdirectorio y archivo, es decir, cero o más niveles de subdirectorios.
También podemos notar el uso de [sS], esta notación de glob indica que acepta sola una vez ya sea la sminúscula o la Smayúscula.
En el arreglo spec_files, su primer elemento es un patrón glob, el cual busca en cualquier subdirectorio relativo al directorio definido en spec_diry que tenga cualquier conjunto de letras al principio pero que terminen con spec.jso Spec.js. Esta definición podría obtener las siguientes rutas de archivos:
/spec/nombre-archivo.spec.js
/spec/nombre-archivo.Spec.js
/spec/helpers/nombre-archivo.spec.js
/spec/helpers/nombre-archivo.Spec.js
/spec/esto/es/otra/ruta/nombre-archivo.spec.js
/spec/esto/es/otra/ruta/nombre-archivo.Spec.js
¿Dónde se utilizan?
En Javascript se utiliza:
Para automatizar tareas que necesitan de la lectura y escritura de archivos
Se utiliza mucho en node.js con herramientas como gulp y webpack
Automatizado de pruebas
Minificado y concatenado para el código en producción.
El patrón de diseño iterador o iterator proporciona una manera de acceder a elementos de un objeto (que contiene algún tipo de datos agregados como un arreglo o una lista) secuencialmente sin exponer su estructura interna.
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
Este patrón de diseño también es conocido como cursor, si has usado cursores para recorrer los elementos obtenidos de una base de datos, ¿Que crees?, ahí estas utilizando el patrón de diseño iterador.
El objetivo de este patrón es poder recorrer y obtener elementos de un objeto sin necesidad de saber como estos datos están estructurados. Además de que la responsabilidad de recorrer los elementos no está en el objeto sino en el iterador.
Un iterador se compone normalmente de los siguientes métodos:
iterador.hasNext() o iterador.hayMas()
iterador.next() o iterador.siguiente()
iterador.current() o iterador.elementoActual()
iterador.rewind() o iterador.rebobinar(), que nos permite posicionar el “cursor” en el primer elemento.
Aquí te dejo como implementarlo en un navegador web:
Podemos notar que el siguiente elemento está determinado por la función iterador.next() el cual suma 2 a la variable index y es por eso que obtenemos los valores 1,3,5,7,9 del arreglo data.
Al final rebobinamos al inicio de data e imprimimos el elemento actual, es decir 1, con el método iterador.current().
MongoDB es una base de datos basada en documentos en formato BJSON que es la forma binaria de JSON, en MongoShell se puede ver el uso de este patrón de diseño:
En este ejemplo se obtienen los documentos de la colección users que tengan una propiedad type igual a 2, luego se recorren uno por uno a través de los métodos cursor.hasNext()y cursor.next().
Es importante saber que son las expresiones de plantillas, estas se utilizan en las interpolaciones y en el Enlazado de propiedades (Property Binding).
Cuando creas un componente, se utiliza HTML para crear su plantilla, esto es bueno, no tienes que aprender mucho de otra sintaxis para plantillas, aun así angular incorpora una pequeña sintaxis, que, aunque pueda ser nueva, es de gran utilidad y en esta publicación veremos expresiones de Javascript, interpolación y property binding en las plantillas de angular.
En las plantillas de angular cualquier elemento HTML es valido, a excepción de elementos como <html>, <head>, <base>, los cuales no tiene que estar en una plantilla de angular porque las plantillas de angular se “dibujan”dentro de la etiqueta <body>.
Otra excepción de suma importancia es la etiqueta <script>, esta etiqueta no se debe usar en las plantillas por el riesgo que se corre a ataques de XSS. Afortunadamente Angular previene XSS a través de sanitización, esta técnica convierte texto potencialmente ejecutable (código no deseado) a texto totalmente seguro.
¿Qué son las expresiones de plantillas?
Las expresiones de plantillas no son más que expresiones de Javascript normales con ciertas limitaciones. Veamos dos ejemplos:
En Interpolación se utiliza la sintaxis {{expresion}}:
<h3>2 + 2 es igual a {{2 + 2}}</h3>
El resultado es:
<h3>2 + 2 es igual a 4</h3>
En enlazado de propiedades se utiliza la sintaxis [propiedad]="expresion":
<h2 [hidden]="oculto">Ejemplo Enlazadode propiedades</h2><input [hidden]="oculto" value="Este es un input oculto">
En el ejemplo, debido que la propiedad ocultoes un boleano igual a true, el h2y el inputpermanecen ocultos. El mismo resultado se obtiene si usamos el comparador de igualdad:
<h2 [hidden]="oculto === true">Ejemplo Enlazadode propiedades</h2><input [hidden]="oculto === true" value="Este es un input oculto">
Vemos que dentro de la sintaxis de doble llaves existe una operación de suma y usamos el operador de igualdad en oculto === true, es decir, podemos utilizar Expresiones de Javascripten nuestras plantillas, aunque podemos utilizar expresiones de Javascript, no todo está permitido.
Las expresiones Javascript que producen efectos colaterales no se deben utilizar y NO están permitidas:
Las asignaciones (=,+=,-=, *=, etc)
El operator new
Las Expresiones consecutivas con ;o ,. Ejemplo {{1+1;2+2}}
Los operadores ++y --
Los operadores a nivel de bits |y &
Una característica importante en las expresiones de plantillas y que es distinta de las expresiones Javascript normales es que se pueden utilizar los siguientes operadores, pero ojo, no son operadores a nivel de bits:
Operador de Tuberia |
Operador de Guardia contra valores null o indefinidos, muy util en acceso a datos, ?.
Operador para vereficar referencia NO Nulla, !
Estos tres últimos operadores los veremos a detalle en otra publicación.
Interpolación
La interpolación nos permite obtener información en una aplicación, genera un enlacecon el origen de la información, es decir, si los datos de origen cambian, la interpolación actualiza ese cambio en la vista. En otras palabras, reacciona al cambio de datos.
Ejemplo, contenido de src/app/app.component.html:
<div><h2>Hola {{nombre}}</h2><h2>{{"cadena".split('').reverse().join('')}}</h2> <h2>{{false ? 'SI':'NO'}}</h2><imgsrc="{{logo}}"><h3>2 + 2 es igual a {{2 + 2}}</h3><h2 [hidden]="oculto">Ejemplo Enlazadode propiedades</h2> <input [hidden]="oculto" value="Este es un input oculto"><h2 [hidden]="oculto === true">Ejemplo Enlazadode propiedades</h2> <input [hidden]="oculto === true" value="Este es un input oculto"><button (click)="cambiarNombre()">Voltear nombre</button></div>
Ejemplo en acción, revisa el archivo src/app/app.component.ts:
En el ejemplo tenemos un componente llamado my-appdefinido en el archivo src/app/app.component.ts, la plantilla del componente está definida en la propiedad templateUrldel decorador @component, carga un arhivo html externo.
Podemos ver que cuando damos clic en el botón Voltear textola propiedad nombrees cambiada invirtiendo los caracteres, se invierte los caracteres a través del método cambiarNombre. Y la reacción a este cambio esta enlazado con la interpolación {{nombre}}.
También se puede utilizar interpolación en atributos, en el ejemplo anterior para mostrar la imagen se utilizó:
<imgsrc="{{logo}}">
Otro ejemplo:
<h3>2 + 2 es igual a {{2 + 2}}</h3>
¿De dónde se obtienen los valores de las expresiones de plantilla?
Normalmente los valores estan definidos en el componente como vimos en el anterior ejemplo, nombrey logoestán definidos como miembros de la clase y en el constructor se les define su valor.
Pero también se puede definir propiedades en el contexto de la plantilla llamadas variables de plantillas, existen dos tipos de estas variables:
En este otro caso se ocupa el carácter #y luego el nombre de la variable de referencia que deseas crear. Con esto se puede utilizar la variable en interpolación como se ve en {{varReferencia.value}}.
La jerarquía o prioridad del valor final obtenido en las expresiones de plantillas es así:
Variables en plantilla, input y de referencia.
Directivas
Componentes
Para ilustrar la prioridad, veamos el ejemplo, en la parte donde se utiliza la directiva *ngForpara recorrer el arreglo gente, ahí se define una variable de input persona, y después se accede a la propiedad nombre de cada persona, podemos notar que debido a la jerarquía arriba listada se tomo primero en cuenta la variable de plantilla personaantes que el miembro personadel componente. El miembro personaes un string “soy otra persona”y nunca se imprime dentro de la lista de personas.
Cuando uses una expresión de plantilla, sigue estos consejos:
Tu expresión debe ser rápida de ejecutar porque no va a ser la única en toda tu plantilla. Si es necesario, considera guardar los resultados de las expresiones que se van a utilizar varias veces en la plantilla y asi la expresion no se ejecuta varias veces.
Utiliza el principio de mantener todo estúpidamente simple, no uses complejas expresiones porque genera mucho ruido en la plantilla, para expresiones más complejas utiliza la clase del componente, y aún ahí considera el principio KISS (Keep It Simple, Stupid).
Investiga el funcionamiento de detección de cambios de angular para mantener tus expresiones lo más eficientes posibles, en una futura publicación explicaré la detección de cambios y como nos ayuda a mejorar el rendimiento de nuestro aplicación.
En este artículo vamos a utilizar el API de Elementos HTML personalizados) para crear nuevas etiquetas y utilizarlas en nuestro código HTML, en futuras publicaciones explicaremos como se usan en conjunto con los otros 3 estándares. Para crear un componente web se utilizan 4 tecnologías principales estándares de la web.
Custom elements o elementos HTML personalizados.
Shadow DOM, DOM en las sombras.
Carga de módulos o componentes externos.
HTML imports con la etiqueta <link rel="import">.
<script type="module">, cargando módulos usando el tag script. Esta tecnología sustituye a los html imports.
Cada uno de estos ciclos es un evento único; dieta, elección, selección, estación, clima, digestión, descomposición y regeneración, difieren cada vez que ocurren. Por lo tanto, es el número de estos ciclos, grandes y pequeños, lo que decide el potencial de diversidad. Deberíamos sentirnos privilegiados de ser parte de esa renovación eterna. Con solo vivir hemos logrado la inmortalidad como hierba, saltamontes, gaviotas, gansos y otras personas. Somos parte de la diversidad que experimentamos en todos los sentidos. Si, como nos aseguran los científicos, todos tenemos moléculas de Einstein, y si las partículas atómicas de nuestro cuerpo físico llegan a los límites más externos del universo, entonces todos somos en efecto componentes de todas las cosas. No nos queda ningún lugar adonde ir si ya estamos en todas partes, y esto es, en verdad, todo lo que tendremos o necesitaremos. Si nos amamos a nosotros mismos, deberíamos respetar todas las cosas por igual y no reclamar ninguna superioridad sobre lo que son, en efecto, nuestras otras partes. ¿Es la mano superior al ojo? ¿El hijo de la madre?
Bill Mollison
Elementos HTML Personalizados
El estándar Custom elements nos indica dos maneras de extender la funcionalidad del HTML:
Crear nuestros propios elementos desde cero, nuevos elementos a los que le agregamos toda la funcionalidad que sea necesaria.
Extender la funcionalidad de elementos ya existentes. Lamentablemente esta característica no está soportada por todos los navegadores modernos. En la versión v0 si había soporte, pero esa versión ya está obsoleta.
Desde la versión 67 de chrome esto funciona correctamente, Firefox lo tiene en desarrollo, Edge lo va a implementar, lamentablemente safari decidió no implementarlo.
Más información en https://www.chromestatus.com/feature/4670146924773376
Para entender la diferencia, en el primer caso podríamos crear un elemento llamado <mi-boton>, al que tendríamos que agregar estilos y funcionalidad desde cero para que se comporte como un botón.
En el segundo, podemos crear un elemento <mi-boton-extendido>, el cual extiende de la etiqueta <button>, entonces este componente si tendría los estilos, eventos y demás comportamientos de un botón, es decir, hereda el comportamiento de <button> y entonces solo se le agregaría algún comportamiento extra para cumplir con el objetivo en mente.
Si en los ejemplos no lanza el alerta especificado en el código, siempre puedes presionar “edit on codepen” para que el alerta funcione y puedes ver el código en un espacio más grande.
Crear un nuevo elemento desde cero
Veamos la primera forma para crear un nuevo tipo de elemento, desde cero.
Hay algunas cosas importantes que remarcar en el código:
Todos los elementos deben tener un prefijo, esto es un requisito para evitar que en futuras versiones de HTML las nuevas etiquetas colisionen con los elementos creados por ti u otros programadores.
Podemos registrar un elemento en dos pasos, creando la clase y pasando su referencia como parámetro en el método customElements.define o utilizar una clase anónima como se hizo con <mi-boton-2> directamente en el método customElements.define.
Una clase en Javascript no es una clase como en otros lenguajes de programación orientada a objetos, realmente es como un tipo de función especial que te permite utilizar herencia de prototipos de una forma más familiar y limpia.
En el constructor siempre debemos de invocar la función super(), de esta manera obtenemos la herencia, pues provoca que se invoque este mismo método en la cadena de prototipos/herencia. Si no se invoca, el navegador web te mostrara un caught ReferenceError: Must call super constructor in derived class before accesing 'this' or returning from derived constructor.
Para establecer estilos se usa la nuevas etiqueta creadas mi-boton y mi-boton-2. Al ser nuevas etiquetas, cualquier selector de css puede funcionar, hablamos de selector de clase, el id, pseudoselectores y pseudoelementos.
Extender la funcionalidad de elementos ya existentes
Ahora vamos a crear un nuevo elemento basado en uno ya existente, solo pondremos el ejemplo del código, realmente como mencionamos antes, no todos navegadores aún soportan este estándar, esperemos que en futuras versiones lo hagan.
Las principales diferencias cuando extendemos la funcionalidad de elementos nativos es que seguimos utilizando el nombre de la etiqueta nativa y agregamos el atributo is para indicar que será del tipo elemento que definimos. Esto en código HTML.
Pero en código Javascript es necesario en la definición (método customElements.define), utilizar un tercer parámetro donde podemos indicar de que elemento HTML vamos a extender, extends. Y definir la propiedad is a través de código JS.
Métodos del ciclo de vida de un elemento
Los custom elements tiene funciones que se ejecutan en un determinado momento de su existencia, de tal manera que el autor puede ejecutar acciones, cambios o inicialización de datos en uno o mas momentos del ciclo de vida de un componente.
Si revisas la consola de la página creada por codepen, el orden en que son ejecutados estos callbacks es:
constructor: Cuando el elemento es creadoattributeChangedCallback: Cuando cambia un atributoconnectedCallback: Cuando el elemento es insertado en el documento
Para probar disconnectedCallback solo inspecciona el elemento <mi-mensaje> y elimínalo. Un mensaje de alerta parecerá informando de la eliminación.
Cuando se crea el elemento, attributeChangedCallback se ejecuta al definir por primera vez el atributo antes de que el elemento sea insertado en el DOM.
Sincronización de atributos y propiedades
Recuerda que las propiedades y los atributos son cosas diferentes, aunque los atributos se ocupen para reflejar el estado de un elemento, no son lo mismo. Un atributo se ocupa normalmente para declarar información del elemento en el código HTML y reflejar su estado, una propiedad forma parte de la instancia del elemento.
Para obtener un atributo se utiliza elemento.getAttribute(nombreAtributo), para obtener una propiedad se utiliza elemento.propiedad.
Para definir un atributo se utiliza elemento.setAttribute(nombreAtributo, valor), para definir una propiedad se utiliza elemento.propiedad = valor.
Los atributos se guardan en una propiedad elemento.attributes de la instancia del elemento.
Para entender mejor esto, vamos a crear un ejemplo un poco más complejo, donde se implementa la sincronización de atributos, propiedades y el estado del elemento. Este nuevo elemento consta de dos propiedades principales, msj y casiVisible, estos se sincronizan con los atributos msj y casi-visible.
Cuando el atributo casi-visible está declarado, el elemento se opaca hasta casi desaparecer, además el borde negro desaparece.
Cuando decimos que se sincronizan, es que un cambio en la propiedad, se refleja en el atributo y viceversa.
Puedes hacer varias pruebas, inspeccionando los elementos, agrega y elimina el atributo casi-visible.
También puedes inspeccionar el elemento y modificar el atributo msj para ver que sucede.
Las mismas pruebas las puedes hacer con las propiedades, utilizando google chrome inspecciona los elementos y en la consola ejecutas el código de abajo:
$0.msj ='HOLA MODIFICANDO EL MENSAJE';$0.casiVisible =false;// muestra el elemento$0.casiVisible =true;// casi oculta el elemento
En todos los casos notarás cambios en el estado del elemento y en el contenido del mensaje.
En siguientes publicaciones veremos como utilizar el estándartemplate o plantilla y shadow DOM (DOM en las sombras), luego veremos el uso JS modules, para al final crear componentes completos y ver como se comunican entre ellos.
Para entender los componentes web, tenemos que entender un poco a la naturaleza. Como seres humanos a veces se nos olvida que somos parte de la naturaleza y que el desarrollo de software siempre trata de representar el mundo real.
Veo el micelio como la Internet natural de la Tierra, una conciencia con la que podríamos comunicarnos. A través de la interfaz entre especies, es posible que algún día intercambiemos información con estas redes celulares sensibles. Debido a que estas redes neurológicas externalizadas sienten cualquier impresión en ellas, desde pasos hasta ramas de árboles que caen, podrían transmitir enormes cantidades de datos sobre los movimientos de todos los organismos a través del paisaje.
Paul Stamets
Los componentes web tratan de representar el mundo real
La programación y el desarrollo de software se inspira en la naturaleza. El desarrollo de software al ser una actividad humana y social, siempre se usa en busca de solucionar problemas reales de nuestro entorno.
Antes de explicar que es un componente web me gustaría mucho compartir contigo esta información sobre diseño atómico. Interesante la relación con los átomos, moléculas y organismos ¿Verdad?. La naturaleza nos enseña mucho, pues está diseñada de una manera superior y el ser humano puede aprender mucho de este gran sistema. El mundo mismo es un sistema, el universo es un sistema.
Teniendo una noción de estos componentes podemos encontrar su relación con el desarrollo de software y con ello aprender a diseñar mejor nuestros sistemas computacionales.
Comunicación entre componentes
Los átomos se comunican y forman moléculas, las moléculas se comunican y forman organismos y como estos también se comunican y forman organismos más complejos. Luego esos organismos más complejos forman sistemas completos, como el sistema respiratorio o el mismo ser humano. ¡Ups!, creo que acabo de describir la esencia de la programación orientada a objetos, porque es lo mismo, desde la comunicación entre funciones, clases, componentes, módulos, hasta la comunicación entre aplicaciones.
Imagina como los pulmones forman parte del sistema respiratorio, y como este último forma parte de un ser humano. El cerebro se encarga de indicarle a los pulmones cuando contraerse y cuando expandirse sin que nosotros seamos conscientes de esos movimientos. ¿Te das cuenta de la comunicación entre el cerebro y los pulmones?
También los pulmones se comunican con otro componente llamado corazón. Los pulmones limpian la sangre llena de dióxido de carbono y agregan oxígeno. Es en ese momento en que esa sangre rica en oxígeno se envía al corazón. El corazón bombea la sangre a todas las partes de nuestro cuerpo. ¿Te das cuenta de todas las comunicaciones que existen entre los órganos (componentes)?
Dicho todo el rollo anterior y después de darle por lo menos un vistazo al diseño atómico. Nos damos cuenta de la importancia de los componentes que conforman el diseño de algo más complejo. Y en nuestro caso los componentes con los que construimos nuestras aplicaciones web.
¿Qué es un componente web?
Entonces, ¿Qué es un componente web? Un componente web es lo mismo que explicamos en los párrafos anteriores solo que con el contexto de aplicaciones web. Dado que es tecnología web, se usa mucho javascript, CSS y HTML, cuando se crea un componente web. Se crea una nueva etiqueta HTML para ser reutilizada tal como usamos las etiquetas h1, p, o form.
Diseño atómico, átomos, moléculas, organismos y plantillas
Tomando como ejemplo nuestro sistema respiratorio y utilizándola como analogía a la multiplicación de números. Primero, en lugar de nariz, laringe y traquea para ingerir aire, tenemos elementos de entrada como inputs y botones para insertar los números.
En los pulmones se obtiene el oxígeno para crear una combustión interna para luego mandar al corazón sangre rica en oxígeno, también se despide el resultado de la combustión en forma de CO2. En la multiplicación, tenemos un componente Multiplicación de números que permite recibir dos números, multiplicarlos y mostrártelos en la aplicación a través de texto.
¿Cómo empezar a utilizar los componentes web?
Ahora, la creación de componentes web está basado en cuatro principales estándares de la web. Estos nos permite crear componentes reutilizables y encapsular su funcionamiento y al mismo tiempo permiten la comunicación entre ellos para crear sistemas robustos.
Custom elements o elementos personalizados
Shadow DOM, DOM en las sombras.
HTML Templates, Plantillas HTML.
<script type="module">, cargando módulos usando el tag script.
Antes se usaba HTML imports, importar componentes a través del tag <link rel="import">
Actualmente el soporte de estos cuatro estándares en los navegadores web es el siguiente. Tomado de https://www.webcomponents.org/.
Soporte de componentes web en navegadores
La imagen fue tomada de webcomponents.org, y si quieres saber más a detalle sobre el soporte de los navegadores, aquí te dejo la lista:
También existen frameworks como Angular y Vue, y librerías como React, que se basan en componentes. Aunque no ocupen los cuatro estándares principales, se utilizan para crear aplicaciones web robustas con los mismos principios.
Aquí hay un compendio inicial de algunos de ellos: