Antes de todo, estoy en el proceso de aprendizaje de React y en esta publicación voy a explicar, según mi entendimiento, los métodos del ciclo de vida de un componente con React.
A partir de la versión 16.3 de React se agregaron nuevos métodos del ciclo de vida de un componente para mejorar el rendimiento, buenas practicas y así obtener una mejor calidad de los componentes creados.
Principalmente este cambio es debido a componentes con funcionalidad asíncrona, esto es muy importante porque normalmente el mundo real es asíncrono y los componentes que creamos son utilizados en el mundo real por personas.
Por esta razón también se empiezan a dejar de utilizar los siguientes métodos, esto sucederá a partir de la versión 17 de React:
componentWillMount()
componentWillRecieveProps(nextProps)
componentWillUpdate(nextProps, nextState)
Dado que los anteriores métodos se dejaran de usar en la version 17, los siguientes métodos son los recomendados a utilizar en un componente:
Y para visualizar su relación, aquí está un diagrama de flujo:
Diagrama de los métodos del ciclo de vida de un componente en React
Si observamos el diagrama, el método static getDerivedStateFromProps(nextProps, prevState) sustituye al método deprecado componentWillReceiveProps(nextProps), también parece ser que el método getSnapshotBeforeUpdate(prevProps, prevState) sustituye al método deprecado componentWillUpdate(nextProps, nextState).
Para fines de demostración vamos a crear un componente Padre y otro componente Animal (componente hijo), lo ideal es que el componente Padre maneje todo el state, pero para demostrar el funcionamiento de los métodos ocuparemos algo de state en nuestro componente Animal.
constructor(props)
El constructor es un método de la mayoría de los lenguajes de programación orientada a objetos, y se utiliza para crear la instancia de una clase. En react el constructor se usa para crear la instancia de nuestro componente.
Cabe mencionar que después de la ejecución de este método, nuestro componente aún no se pinta en nuestro navegador, al proceso de pintado, es decir, insertarlo en el DOM, se le llama Montar o Mount en ingles.
Como buena practica de programación es importante ejecutar super() dentro de un constructor para que realice cualquier llamada a constructores padres.
En el caso de react se debe llamar con las props recibidas en el constructor, o sea, super(props), esto nos permite poder acceder a las props a través de this.props dentro del constructor.
El constructor se usa normalmente para las siguietes dos cosas:
Definir el estado local con un componente a través de this.state.
Para enlazar el objeto this(la instancia de nuestro componente) a los métodos que son utilizados en el método render(). Estos métodos son usados como manejadores de eventos
El estado de nuestro componente en el constructor se define así:
Si no defines ningún estado en el constructor, entonces no lo necesitas.
Si se te ocurre definir el state usando las props pasados como parámetros probablemente es mejor definir el state en un componente padre o en la raíz de todos los componentes porque el estado no estará sincronizado con los cambios de las propiedades.
Para enlazar la referencia de la instancia de nuestro componente a los métodos que son utilizados en el método render() y que normalmente son los manejadores de eventos:
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}this.cambiarAnimal=this.cambiarAnimal.bind(this);}cambiarAnimal(){this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Ahora el método this.cambiarAnimal podrá acceder a la instancia de nuestro componente a través de this y así utilizar this.setState() para cambiar el estado.
Existe otra opción para utilizar métodos de nuestra clase como manejadores de eventos, con el uso de funciones flecha (arrow functions).
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}}cambiarAnimal=()=>{this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Este método es estático, sí, debe tener el modificador static que indica que este método no está enlazado a alguna instancia del componente, sino más bien a su clase. Se invoca después de instanciar un componente y también cuando el componente recibe cambios en las propiedades.
Debe tener siempre un valor de retorno, ya sea un objeto para actualizar el state o null si no se quiere actualizar el state en relación con los nuevos valores de las props recibidas. Es importante saber que este método se ejecuta también cuando un componente padre provoca que el componente hijo sea de nuevo renderizado, por esta razón debes comparar valores anteriores con los nuevos para evitar mandar a actualizar el state cuando no hubo realmente un cambio.
Podemos razonar que este método nos puede servir para mantener sincronizado nuestro state (o solo una parte) con las props pasadas desde un componente padre.
Por el momento en nuestro ejemplo del componente Animal solo visualizaremos los datos y regresaremos null porque no queremos actualizar el estado, además el atributo src de nuestra imagen se actualiza cuando la propiedad src del componente cambia.
Lo siguiente realmente no es necesario, pero para visualizar la ejecución de este método supongamos que dentro de nuestro componente Animal vamos a manejar la url(src) de la imagen del animal en this.state.src, así:
constructor (props) {this.state={ src:props.src};}static getDerivedStateFromProps (nextProps, prevState) {if (prevState.src!==nextProps.src) {// necesario para actualizar la imagen cada vez que cambie this.props.srcreturn{ src:nextProps.src};}returnnull;}render() {return (<imgclassName="cat__img"src={this.state.src} /> );}...
Ahora prueba el código aquí, y revisa los mensajes de la consola, por el momento solo nos estamos enfocando en el constructor(props) y static getDerivedStateFromProps(nextProps, prevState):
render()
Este método es obligatorio en cualquier componente, pues como su nombre lo dice, se utiliza para obtener los elementos finales a visualizar o pintar en el navegador. Debe ser una función pura, es decir, no debe modificar las props, no debe modificar el state ni realizar operaciones del DOM.
Según mi entendimiento, el resultado de este método es utilizado por ReactDOM.render() para insertarlo en el DOM del navegador. Si el componente en cuestión ha sido insertado previamente, solo se muta el DOM lo necesario para reflejar los nuevos cambios, esto quiere decir querender() regresa los objetos necesarios para que en otro lugar sean insertados en el DOM.
Esto se puede comprobar si observas la consola del anterior ejemplo y luego das clic sobre el botón “Cambiar animal” entonces verás que el método render() es ejecutado antes de getSnapshotBeforeUpdate() y componentDidUpdate().
Con esto tengo una duda, ¿En qué momento se modifica el DOM?, yo creo que se modifica el DOM después deReactDOM.render()y antes de quecomponentDidUpdate().
Este método se ejecuta cuando nuestro componente está listo en el DOM, siguiendo el razonamiento explicado en el método render(), se ejecuta después de que React inserte el DOM, y antes del método `render()`. Por eso es útil para realizar llamadas ajax y operaciones con el DOM como agregar eventos y/o modificar elementos internos.
Dentro de este método es seguro cambiar el state, pero si ejecutamos this.setState() provocara que nuestro componente se vuelva a renderizar.
La documentación oficial de React nos advierte tener cuidado con esto, pues puede causar problemas de rendimiento por renderizar nuestro componente varias veces. Sin embargo es necesario para los casos de tomar medidas y posiciones de algunos elementos antes de renderizar, por ejemplo el tamaño y posición de modales y tooltips.
Para ver el uso de este método veamos el siguiente ejemplo, si revisamos la consola veremos que render() se ejecuta dos veces, también si damos clic en el botón Cambiar animal, se nota que de nuevo render() se ejecuta dos veces.
¿Por qué sucede esto?, sucede porque dentro del método componentDidMount() agregamos un escuchador de eventos para la carga de la imagen del animal, al ejecutarse this.onImgLoad().
`this.onImgLoad()` invoca a this.setState() y esta función provoca que el componente se vuelva a renderizar para mostrar las medidas exactas de la imagen cuando se termina de cargar.
shouldComponentUpdate(nextProps, nextState)
En versiones actuales de React, este método se ejecuta para decidir si los cambios en las props o el state merecen que se vuelva a renderizar el componente con estos nuevos datos.
El valor de retorno de esta función es true o false. Si el resultado de este método es true, los métodos render(), getSnapshotBeforeUpdate() y componentDidMount()no se ejecutan.
Recibe como parámetros las nuevos valores pros y del state, con estos valores y los valores actuales de nuestro componente podemos condicionar si es necesario volver a renderizar o no, de esta manera podemos mejorar el rendimiento manualmente.
Si no implementamos este método en nuestro componente, React toma como resultado el valor true, por lo que siempre se volverá a renderizar. El resultado no influye en los componentes hijos, si en un componente padre el resultado es false, esto no impide que componentes hijos necesiten volver a ser renderizados.
Es importante mencionar que en la documentación indica que tal vez en futuras versiones de React, este método no impida un renderizado del componente, o sea, que en un futuro si este método regresa falseaun así se ejecutaran los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
Esto último me deja con un sabor amargo, actualmente este método es un buen lugar para mejorar el rendimiento de nuestro componente porque evitamos el re-renderizado en situaciones que no sean necesarias, pero después en futuras versiones cabe la posibilidad de perder esta habilidad, entonces quiero pensar que deben existir otras maneras de mejorar este caso de rendimiento, ¿Alguien tiene alguna idea?.
Veamos un ejemplo, en el anterior método componentDidMount() mencionamos que agregamos un escuchador de eventos al finalizar la carga de la imagen para poder obtener sus medidas, estás medidas las mostramos en nuestro componente, pero esta el caso de dos imágenes de perros que tiene la misma medida, 128px - 128px, entonces el ancho y el alto de la imagen no cambia, por lo que no es necesario volver a renderizar nuestro componente.
Si cambiamos de entre el perro de raza chihuahua y el perro ladrando, podemos ver en la consola que el último método ejecutado es el shouldComponentUpdate(), como el resultado fue false, no se ejecutaron de nuevo los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
getSnapshotBeforeUpdate(prevProps, prevState)
Este método se ejecuta después de render() y antes de componentDidUpdate(), el valor que regresa la ejecución de este método se convierte en el tercer parámetro llamado snapshot de componentDidUpdate(prevProps, prevState, snapshot), este método debe regresar algún valor o null, si no es así, React nos advertirá con algo parecido al siguiente warning en la consola:
Warning:Animal.getSnapshotBeforeUpdate(): A snapshot value (or null) must be returned. You have returned undefined.
Además recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Este método puede regresar cualquier tipo de valor, por ejemplo puede regresar datos del DOM como cuantos elementos existen en una determinada lista de elementos o la posición del scroll antes de que el componente sea actualizado a través de ReactDOM.render()(si nuestra hipótesis explicada en el método render() es correcta).
Si revisamos el código de getSnapshotBeforeUpdate() y componentDidUpdate() y además revisamos la consola, notaremos que getSnapshotBeforeUpdate() le envía a componentDidUpdate el numero de elementos del DOM que contiene el componente en cuestión, que son 2, el párrafo con las medidas de la imagen y la imagen del animal.
Este método se ejecuta cuando el componente ha sido actualizado totalmente, y es reflejado en el DOM de nuestra aplicación, recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Aquí se puede trabajar con el DOM del componente dado que este mismo ha sido actualizado, además se puede realizar operaciones como obtener datos remotos según los cambios de las props o state.
No se ejecuta la primera vez que se usa el método render(), es decir, cuando se monta el componente.
En la consola podemos ver los datos, prevProps, preState, y snapshot, este último tiene el valor 2. También vemos this.props y this.state
componentWillUnmount()
Este método se ejecuta justo antes del que el componente sea desmontado del DOM, es un buen lugar para liberar recursos y memoria. Un ejemplo claro es la eliminación de escuchadores de eventos que ya no se van a necesitar, también se pueden cancelar peticiones remotas que se estén ejecutando actualmente dado que estas seguirán su proceso aún desmontando el componente.
En el ejemplo de abajo se ilustra como se elimina un escuchador de evento load para la carga de la imagen del animal.
En HTML, los atributos juegan un papel importante porque permiten definir cierta configuración o comportamiento a los elementos HTML, permitiendo obtener diferentes resultados.
Esta publicación es la segunda parte de una serie de publicaciones sobre ¿Cómo puedes crear tu primera página web?, aquí puedes encontrar la primera parte.
En la primera parte vimos como tener las etiquetas(tags) básicas para tu página web, ahora veremos que son los atributos y CSS.
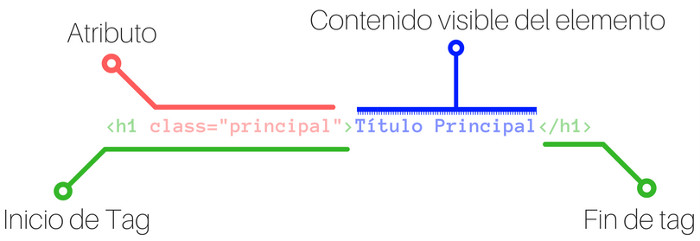
Primera recordemos como es una etiqueta o tagcon la siguiente imagen.
Observando la imagen aprendemos la sintaxis para agregar atributos, es la parte de color rojo, en este caso classes el atributo, seguido de un signo de =y luego entre comillas el valor que queremos asignarle.
Veamos los atributos starty reversedpara una lista ordenada:
Otros atributos no necesitan algún valor, porque su solo presencia es suficiente, uno de ellos es el atributo reversedy open.
Ahora debemos tomar en cuenta que no todos los atributos son aplicables a todas las etiquetas, los atributos reversedy startson atributos específicos para listas ordenadas, es decir, la etiqueta <ol></ol>y no tienen ningún efecto en otros elementos.
Con lo anterior en cuenta podemos discernir que existen atributos Globalesy No globales, los atributos Globalestienen efecto sobre todas las etiquetas, mientras los No Globalessolo a un grupo de etiquetas o a veces solo a una etiqueta en específico.
Entender que atributos son globales es de mucha ayuda, aun así no hay prisa en aprenderlos de memoria, siempre que tengas dudas revisa la lista de atributos globales aquí.
¿Qué es CSS?
Recordemos que…
HTML permite crear el contenido de nuestro página o aplicación de manera organizada. CSS se encarga de la apariencia visual del contenido generado por HTML, con CSS podemos establecer el diseño, colores, tamaño de letra, dimensiones de cada elemento, posiciones y alineados, bordes, sombras y demás características de diseño. Y finalmente Javascript te permite interactuar dinamicamente con la aplicación, claro ejemplo del uso de Javascript son las notificaciones de facebook, el chat de este mismo, cuando damos me gusta, creamos una publicación o escribimos un comentario.
La sintaxis principal de CSS se llama regla. Una regla se comforma de 2 partes, selectory declaración.
Un selectorpermite seleccionar uno o más elementos HTML de nuestra página. CSS es otro lenguaje diferente a HTML, así que el selector de ejemplo no llevan los signos mayory menorque, el selector NO es así <p>.
Cada declaraciónpuede tener uno o más pares de propiedad: valor;, cada par de propiedad: valor;realiza un cambio visual en los elementos seleccionados por el selector.
Los atributos también son muy utiles a la ahora de agregar estilos y diseño de una página web, esto se debe a que la sintaxis del selectortambién hace uso de los atributos para seleccionar uno o más elementos.
Los estilos se pueden agregar usando la etiqueta <style></style>, y esta etiqueta puede existir dentro del <body>o <head>.
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Mi primera página web</title>
<!-- Agrgando estilos dentro de HEAD -->
<style>
p { font-size: 12px; color: #555555; }
</style>
</head>
<body>
<!-- Agreando estilos dentro de BODY -->
<style>
p { font-size: 12px; color: #555555; }
</style>
</body>
</html>
Lo más recomendable es poner nuestros estilos en un archivo aparte con extensión .csse importarlo desde nuestro código html dentro del elemento <head>usando la etiqueta <link>.
Con lo que sabemos de CSS veamos un ejemplo de lo que podemos conseguir:
En la primera regla vemos que el selector es html, con esto sabemos que al elemento html se le van a aplicar estilos. También sabemos que dentro de htmlexisten las demas etiquetas que completan nuestra página como elementos hijos.
Una de las propiedades más comunes es font-size, la cual define el tamaño de la letra del texto. El valor de esta propiedad se define con un número y una unidad, en este ejemplo la unidad es pxque quiere decir pixel.
Al elemento htmlse le llama muchas veces rooto raízy en la mayoría de los navegadores web tiene un font-size: 16pxpor defecto. En este caso el valor por defecto lo estamos disminuyendo 2 pixeles.
html {
font-size: 14px;
}
Existen más unidades, rem, em, %, vhy vwque veremos a detalle más adelante.
Después tenemos nuestro selector body, en la declaración se define el tipo de letra o fuente con la propiedad font-familyy las fuentes se establecen entre comillas, las únicas fuentes que pueden no llevar comillas porque son un estándar en los navegadores web son serif, sans-serif, monospace, cursivay fantasy.
Cada nombre de fuente es separada por una coma(,), de esta manera el navegador va tomando de izquierda a derecha el tipo de fuente, si no existe la primera fuente en tu computadora, va por la segunda y así sucesivamente hasta encontrar una existente.
body {
/*
* ESTO ES UN COMENTARIO:
* Fuentes estandar disponibles en el navegador:
* serif, sans-serif, monospace, cursive, fantasy
* Estas no llevan comillas
*/
font-family: "Helvetica", "Verdana", "Arial", sans-serif;
}
Ya mencionamos que CSS significa Hoja de Estilo en cascada, la parte de cascadase refieren a la herenciay la precedenciade las reglas que definimos, en el caso de font-familyagregado al elemento body, esta propiedad la heredan todos los elementos hijos, por lo que todo nuestra página tendrá el mismo tipo de letra.
Otra propiedad es line-height, la cual define el espacio vertical de las líneas de un texto, podemos notar su funcionamiento en el primer y segundo párrafo, line-height: 1y line-height: 2respectivamente.
Para seleccionar el segundo párrafo ocupamos el atributoid, este atributo debe ser único por cada elemento, no se debe repetir, este selector siempre selecciona un solo elemento.
Dentro de la declaración de propiedades tenemos una propiedad llamada margin-topesta propiedad define la separación superior del segundo párrafo con el primero.
Algo interesante es que el valor es 2rem, la unidad remse refiere al tamaño de fuente del elemento raíz(root), nuestro elemento raíz es htmly como tamaño de letra le definimos anteriormente con 14pxpor lo que margin-topseria igual a 28px. Esta unidad de medida remnos permite definir tamaños relativos al tamaño de la fuente raíz.
Luego en las listas ordenadas tenemos las propiedades padding-top, padding-right, padding-bottomy padding-left. Estas propiedades definen el espacio que existe entre los bordes de un elemento y su contenido. Dado que el selector es olnos permite seleccionar todas las listas ordenadas de nuestra página.
Ahora tenemos el selector .contorno, donde se define la propiedad border, el cual nos permite resaltar el borde de un elemento, su sintaxis es el grosor del borde, el tipo y por último el color. Con esta regla podemos definir un borde verde a todos los elementos que tengan dentro del atributoclassel valor contorno.
.contorno {
border: 1px solid green;
}
Otra propiedad de gran ayuda es list-style-positionla cual define la posición de la numeración o viñetas de una lista. Dado que el selector es li, nos permite seleccionar todas los elementos de listas de nuestra página.
li {
list-style-position: inside;
}
Más abajo tenemos un selector utilizando el atributoidde la primera lista. En la declaración de propiedades se define el color de fondo con background-color: lightblue.
Luego tenemos otro selector que usa el atributoclass, pero un valor de classsi puede ser utilizado en más de un elemento, esto quiere decir, que este selector nos permite seleccionar todos los elementos de nuestra página web que dentro del atributo classtenga el valor green.
Es importante mencionar que el atributo classpuede tener más de un valor separado por un espacio en blanco.
<ol class="green contorno"></ol>
Por último tenemos un elemento detailscon el atributo opensin ningún valor, su sola presencia indica que ese elemento esta desplegadoo abiertoy cuando está desplegado su color de fondo cambia a azul claro. La notación para atributos que no son idni classes la de corchetes [nombreAtributo].
Para crear una página web necesitas comprender tres sencillas tecnologías muy fáciles de aprender; HTML, CSS y Javascript.
Juntas permiten crear aplicaciones sofisticadas, ejemplo de ellas son instagram, twitter y facebook, a continuación veamos que son estas tecnologías.
HTML
HTML permite crear el contenido de nuestra página o aplicación de manera organizada y estructurada, sin HTML no podrías ver tus fotos en facebook o reproducir videos en youtube.
CSS
CSS se encarga de la apariencia visual del contenido generado por HTML, con CSS podemos establecer el diseño, colores, tamaño de letra, dimensiones de cada elemento, posiciones y alineados, bordes, sombras y demás características de diseño. Sin CSS sería muy difícil de entender tu muro de facebook, todo estaría muy revuelto.
Javascript
Javascript te permite interactuar dinámicamente con la aplicación, claro ejemplo del uso de Javascript son las notificaciones de facebook, el chat de este mismo, cuando damos me gusta, creamos una publicación o escribimos un comentario.
Desde mi punto de vista lo ideal es aprender primero HTML, luego CSS y JavaScript.
Página web solo usando HTML
El siguiente ejemplo muestra como crear tu primera página web, si lo quieres probar en tu computadora, crea un archivo llamado index.html, después copia y pega el código de este ejemplo. Luego para ver tu página recién generada solo realiza un doble clic sobre index.html desde tu explorador de archivos.
A continuación vamos a explicar cada una de las partes de nuestro código.
DOCTYPE
Lo primero que existe en nuestro código es <!DOCTYPE html>, esto indica al navegador las sintaxis y reglas que formaran a nuestra página web. Antiguamente, se utilizaba una definición de doctype mucho más extensa, algo como lo siguiente.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
Pero actualmente la versión corta es más que suficiente, solo no olvides agregarla, porque de otro modo tu contenido será renderizado como una versión antigua de HTML.
Etiqueta HTML
Luego tenemos la etiqueta <html>, indica el inicio de nuestra página web, todas las demás etiquetas deben estar dentro de esta, el final de la etiqueta se marcacon casi el mismo código, pero con una diagonal después del signo <, así </html>. Además, la etiqueta <html> tiene solo dos etiquetas hijas, <head> y <body>, las cuales explicaremos un poco más abajo.
<html>
<head></head>
<body></body>
</html>
Etiquetas
Pero ¿Qué es una etiqueta?, una etiqueta es la unidad principal con la que se crea el contenido de una página o aplicación web.
Partes de una etiqueta HTML
Casi todas las etiquetas tiene su etiqueta de cierre </nombre-etiqueta>, digo casi todas porque la etiqueta DOCTYPE no tiene cierre. No te preocupes, son pocas las que no se cierran. Además, los nombres de etiquetas no son sensibles a mayúsculas y minúsculas, puedes escribir la etiqueta html así <HtmL></HtmL>
Atributo lang en la etiqueta html
Algo que destacar en la etiqueta es que tiene este atributo lang<html lang="es">, el cual quiere decir language y su valor significa spanish.
El atributo lang ayuda al navegador web a seleccionar texto, revisar la ortografía, traducir tu página y convertir el texto en audio para personas con problemas visuales.
Etiqueta head
La etiqueta <head> puede contener lo que se le llama metadatos y demás información que no es visible para el usuario. Es el lugar donde se definen o importan estilos (archivos CSS), código Javascript, y demás datos para que el navegador web pinte la página web.
También sirve para describir la página web a motores de búsqueda, por ejemplo usando metadatos sobre quien es el autor, el título y una descripción corta sobre la página web. El título que mencionamos es el de la página web, el que aparece en la pestaña de tu navegador web.
Adicional, la etiqueta head sirve para agregar metas de terceros como el open graph data creado por facebook y twitter cards creado por twitter.
En nuestro ejemplo, dentro de la etiqueta <head> podemos ver dos etiquetas <meta> descritos a continuación ( meta viene de meta information).
<head><metacharset="utf-8"><metaname="viewport"content="width=device-width,initial-scale=1"><title>Mi primera página web</title></head>
Codificación de caracteres utf-8
En el meta<meta charset="utf-8"> usa un atributo charset con valor utf-8, esto indica la codificación de caracteres de la página y nos permite tener caracteres raros de otros idiomas que de otra manera no se visualizarían correctamente. Ejemplos concretos serian la ñ y vocales con acentos para el idioma español, caracteres en chinos o koreano.
Actualmente, los navegadores web como firefox, chrome y brave corrigen este problema automáticamente cuando se carga la página web. Pero se recomienda usar este meta en caso de que se cargue la página web en un navegador antiguo o alguno navegador web que no corrija esta codificación de caracteres automáticamente
El meta <meta name="viewport" content="width=device-width,initial-scale=1"> es muy útil cuando nuestra página es visualizada en dispositivos móviles, width=device-width permite tomar todo el ancho de nuestra pantalla móvil como el ancho de la página, initial-scale=1 evita que ciertos dispositivos le apliquen algún tipo de escaldo inicial a nuestra página. Con este meta obtenemos un diseño congruente en los dispositivos móviles. De otra forma veríamos una página con un escaldo muy pequeño debido a que el navegador trata de encajar el contenido como si lo estuviéramos viendo en una pantalla más grande de computadora.
Una nota importante es que las etiquetas <meta> y <!DOCTYPE html> no tienen su correspondiente cierre o final de etiqueta, esto es así porque estas etiquetas realmente no tienen contenido visible del elemento como pasa con la etiqueta <html></html>, <body></body> o el encabezado <h1></h1>.
Etiqueta body y etiquetas dentro de body
La etiqueta <body> contiene toda la información visible que deseas mostrar al usuario. Todo el contenido que puedas ver en una página web o aplicación está dentro de la etiqueta <body>.
Etiquetas de encabezados
Después tenemos a la etiqueta <body>, la cual contiene todo el demás contenido visible de nuestra página, dentro tenemos 6 etiquetas, <h1> a <h6>, la h significa Heading (encabezado), se ocupan para mostrar títulos o encabezados, <h1> es el de mayor relevancia y <h6> es el de menor.
Etiqueta para crear párrafos
Más abajo tenemos nuestro primer párrafo, para crear un párrafo se utiliza la etiqueta <p>, p significa Paragraph (parrafo). Luego tenemos dos listas de elementos ordenados y desordenados.
<p> El desarrollo web o programación web utiliza tres principales tecnologías;<strong>HTML, CSS y Javascript</strong>. Juntas permiten crear aplicaciones sofisticadas, facebook es el ejemplo más conocido, también mercadolibre e instagram.</p>
Etiqueta strong
La etiqueta <strong> permite marcar palabras o frases que son importantes, normalmente son palabras que cuando hablamos les damos un énfasis fuerte, con un tono más alto y a menor velocidad porque queremos ser más claros en la comunicación. Es por eso que los screen readers leen el contenido de esta etiqueta con un tono de voz diferente.
<p> El desarrollo web o programación web utiliza tres principales tecnologías;<strong>HTML, CSS y Javascript</strong>. Juntas permiten crear aplicaciones sofisticadas, facebook es el ejemplo más conocido, también mercadolibre e instagram.</p>
<p>Este medicamente debe almacenarse <strong>fuera del alcance de los niños<strong>.</p>
Los navegadores web marcan el contenido en negritas, pero esta etiqueta no debe usarse con el objetivo visual de remarcar un texto en negritas. Para poner texto en negritas por razones solo de diseño puedes utilizar un <span> en conjunto con alguna regla de estilos (CSS).
Etiqueta em
La etiqueta <em> es parecida a la etiqueta <strong> en el sentido de que se usa para enfatizar partes del texto y que los screen readers los lean en diferente tono de voz. Pero no tiene la misma importancia que un texto marcado con la etiqueta <strong>. Se utiliza para que el texto tenga más énfasis que el texto normal.
<p>Recuarda que <em>tienes</em> que apurarte para que te des un poco mas de tiempo<p>
Etiqueta para crear listas de elementos
Para crear una lista de elementos desordenados utilizamos la etiqueta <ul>, ul (Unorder List). Para crear una lista ordenada usamos <ol>, ol (Order List). Estas dos listas contiene tres etiquetas <li>, li significa List Item (Elemento de Lista).
Como vemos, no es difícil crear contenido para nuestra página, lo único que necesitamos saber son los nombres de las etiquetas y para qué nos sirven, aquí puedes encontrarlas. No tienes que memorizarlas, pero si comprender como se usan, así cada vez que necesites de alguna siempre puedes consultar en el anterior enlace.
En futuras publicaciones profundizaremos como funciona nuestro contenido HTML con CSS (Cascade Style Sheet, Hojas de Estilo en Cascada), para terminar incluyendo también Javascript en una tercera publicacion.