Cuando trabajamos con componentes web, normalmente usamos el shadow DOM en los custom elements que creamos debido a que es la manera en que podemos sacarle todo el potencial a este estándar. Pero seguro que más de una ocasión nos hemos preguntado, ¿Qué elementos de HTML NO pueden aceptar Shadow DOM? Bueno, existen dos formas de saberlo.
La especificación del DOM Standard
Herramientas de desarrollador de Google Chrome
La especificación del DOM Standard
La manera más eficiente de saber exactamente que elementos NO soportan shadow DOM es guiarnos por lo que dice la especificación.
La otra opción es usar las herramientas del desarrollador de Google Chrome para ver el shadow DOM de los elementos en una aplicación.
Esta configuración se encuentra en los settings del panel de herramientas para el desarrollador, para ello, debemos dar clic en los tres puntitos verticales y después en settings o solamente presionar F1.
Luego en Preferences -> Elements activamos el checkbox que dice Show user agent shadow DOM.
Ahora podemos revisar sitios web que tengan elementos que soporten shadow DOM, algunos ejemplos son el input, select, audio, video, estos elementos ya contienen shadow DOM y por lo tanto NO podemos adjuntarles uno. En la siguiente imagen se muestra el elemento input :
También existen otros elementos que NO soportan Shadow DOM, ejemplo, img, a, button, br, b, etc.
Tanto los elementos que ya tiene Shadow DOM como los que no lo soportan provocaran el siguiente error al invocar sobre ellos el método attachShadow({ mode: 'open' }). Tal como dice la especificación
Uncaught DOMException: Failed to execute ‘attachShadow’ on ‘Element’: This element does not support attachShadow
Consola de Google Chrome
NotSupportedError: Operation is not supported
Consola de Firefox
Object doesn’t support property or method ‘attachShadow’
Una startup es una institución de seres humanos diseñada para crear un nuevo producto o servicio bajo condiciones de extrema incertidumbre.
Lean Startup toma su nombre de la revolución Lean manufacturing que Taiichi Ohno y Shigeo Shingo desarrollaron en Toyota. Se basaron en Lean Thinking para alterar los sistemas de la cadena de producción y suministros. Entre sus principios está la utilización del conocimiento y creatividad de los individuos, la reducción de los lotes, el método justo a tiempo para los sistemas de gestión de producción y control de inventarios, y una aceleración en las iteraciones. Enfocados en la creación de valor para los clientes y eliminar el desperdicio de esfuerzo.
Lean Startup adapta estas ideas en el contexto de emprendimiento. Para Lean Startup, emprendimiento es un tipo de administración, así es, un emprendedor es un tipo de administrador. La única deferencia es que muchas veces los administradores trabajan en una ambiente más controlado con un producto o servicio existente.
Pero ¿Qué sucede cuando en una empresa se requiere agregar una característica nueva o innovar en un producto existente? Muy probablemente la incertidumbre va a crecer. Y ¿Qué pasaría si una empresa quiere lanzar un nuevo producto o servicio?, en este último caso, podemos decir con seguridad que la incertidumbre es extrema. Esto es lo que realmente sucede en las empresas, porque vivimos en un mundo con cambios sumamente constantes y los administradores necesitan adaptarse a estos cambios.
Debido a esta incertidumbre extrema, una startup no se puede gestionar con los métodos tradicionales, el fracaso en una startup es necesario para el aprendizaje, cometer errores tempranamente para validar tus ideas iniciales y entonces adaptarse mejorando el producto a la necesidad real del cliente.
Con la anterior definición podemos listar los 5 principios de Lean startup:
Emprendedores hay en todas partes
Si ponemos atención la definición de arriba sobre lo que es un emprendedor, podremos comprender que un emprendedor está en todas partes, desde la compañía más grande e internacional, hasta la más pequeña, en cualquier sector, en cualquier industria y en condiciones de extrema incertidumbre.
Emprendimiento es Administración
Así es, una startup es una institución, y requiere un nuevo tipo de administración enfocado en el contexto de condiciones de extrema incertidumbre. Esto quiere decir que una startup no solo se trata del producto, sino de una institución humana completa.
Aprendizaje validado
Una de las claves para el éxito de una startup es el aprender como crear un negocio sustentable, y este aprendizaje se valida usando experimentos frecuentemente de tal forma que se pueda probar cada elemento de la visión de la startup.
Construir-Medir-Aprender
Es el proceso fundamental de una startup, convertir ideas en productos, medir como los clientes reaccionan y aprender si se debe cambiar la estrategia o seguir adelante con la ruta actual. Este proceso está siempre en mejora continua para acelerar la retroalimentación del cliente.
Innovación contable
Como decíamos, necesitamos métodos diferentes, ¿Cómo podemos medir el progreso de la startup?, ¿Cómo definir metas? y ¿Cómo priorizar nuestro trabajo? La contabilidad de una startup no solo son números financieros, lo más importante es medir el valor que le proporcionamos a nuestros clientes y como obtener crecimiento basándonos en ese valor.
Ciclo de retroalimentación Construir-Medir-Aprender y motor de crecimiento
Lean startup es administración de empresas que proporcionan productos o servicios en ambientes de extrema incertidumbre. Aunque existe mucho material sobre administración de negocios, muchas veces no se toma en cuenta la incertidumbre en el que estos negocios se encuentran.
Lean Startup recomienda medir la productividad de manera diferente, este nuevo enfoque existe porque muy a menudo se construye algo que nadie quiere, entonces no importa si se construye a tiempo o dentro del presupuesto si al final nadie va a querer el producto o servicio.
El objetivo de una startup es descubrir lo más pronto posible lo que el cliente realmente quiere y va a pagar por ello, de esta manera se construye solo lo necesario de mucho valor y se evita el desperdicio de tiempo, dinero y esfuerzo. Es una nueva forma de ver el desarrollo de nuevos productos e innovaciones donde se utiliza mucho las iteraciones ágiles con un gran enfoque en el comportamiento del cliente y la combinación de una gran visión de lo que se quiere lograr.
Eric Ríes utiliza la metáfora del automóvil de combustión interna para describir lo que es Lean startup. Dentro de un automóvil existen dos importantes ciclos de retroalimentación:
El motor en sí, llamado Motor de Crecimiento.
Conductor y volante, llamado Construir-Medir-Aprender.
Motor de crecimiento. Se encuentra dentro del motor, cada explosión de los pistones provoca la suficiente fuerza para hacer girar las ruedas y al mismo tiempo impulsa la ignición para la siguiente explosión de los pistones y así generar el continuo movimiento de las llantas de un coche. Esto se traduce a todas las operaciones, marketing y mejoras del producto que se realizan dentro de una institución, esto permite que el motor continúe su función e impulse al crecimiento. En una startup, la mayor parte del tiempo se invierte en poner al 100% este motor, mejorándolo constantemente basándose en los resultados del segundo ciclo de retroalimentación.
No sé mucho de autos, y mucho menos de motores, pero imaginemos que se utilizan distintos motores según el terreno por el cual un coche se desplaza, con esto se explica la relación con el segundo ciclo de retroalimentación, si vamos a nuestro destino a través de una autopista y un camino plano, es claro que necesitamos un motor con mucha velocidad y que aguante la aceleración más rápida durante mucho tiempo, pero si al contrario vamos en un camino de tierra con terreno irregular, con subidas y bajadas bruscas, es necesario un motor con mayor aguante a los cambios continuos entre pausas y aceleraciones, y que por lo tanto además de rapidez para avanzar también necesitamos resistencia a estos terrenos irregulares para llegar a nuestra meta. Necesitamos afinar o cambiar el motor en función del terreno por donde nos desplazamos.
Es importante mencionar, que como el motor de un coche, si no se le da el adecuado mantenimiento y afinaciones necesarias podemos provocar que nuestro coche deje de avanzar, es decir, detenemos el crecimiento de nuestra startup.
Construir-Medir-Aprender. Cuándo se usa un automóvil para llegar a un lugar específico, puedes ir a ese destino incluso si no sabes llegar, revisas un mapa, en el camino puedes preguntarle a personas por indicaciones, cambiar de dirección más de una vez, descubrir un atajo, tomar una ruta que haga que te desvíes pero que inmediatamente lo reconozcas y puedas corregir la dirección hacia tu meta, en fin muchas cosas pueden pasar.
Otra analogía es que si planeas correr un maratón, empieza con unos kilómetros diarios, investiga mejores formas de obtener condición física rápidamente y cada día aumentas un kilómetro o más, vas aumentando tu kilometraje conforme vas mejorando tu condición hasta obtener los kilómetros deseados para tu maratón, es obvio que necesitas hacer esto cuanto antes para fallar lo más pronto posible y aprender antes del día del maratón. No sería inteligente esperar a unos días antes del maratón o peor aún, simplemente correr el maratón completo y fracasar en el intento, tu cuerpo y tu mente no estarán preparados para aguantar el maratón.
En contraste, para lanzar un cohete al espacio se necesita mucha planeación y cálculos, cada cambio de ruta debe estar calculado con anticipación, el minúsculo error hará que un cohete no llegue a su destino o provocar una catástrofe. Hacer las cosas cómo lanzar un cohete, todo a mucho detalle y que el más mínimo error resulte en el fracaso del negocio no es para nada deseable. Por desgracia muchos planes y estrategias de negocios son tratados igual que el lanzamiento de un cohete, lo ideal es ver el plan de negocios tal como manejar un coche.
Por esta razón Lean Startup está diseñado para enseñar cómo gestionar una startup de la misma forma que manejar un carro, en lugar de hacer planes complejos basados en un montón de suposiciones, puedes hacer constantes cambios con un volante llamado Construir-Medir-Aprender.
Con este manejo de volante, podemos saber si de verdad necesitamos cambiar de ruta y cuando hacerlo, a esto se le llama pivotar, o seguir con la ruta actual, esto último llamado perseverar. Una vez que se ha aprendido y construido lo suficiente para que el motor de crecimiento esté en óptimas condiciones, se puede escalar y crecer con la máxima aceleración gracias a los métodos que Lean Startup ofrece.
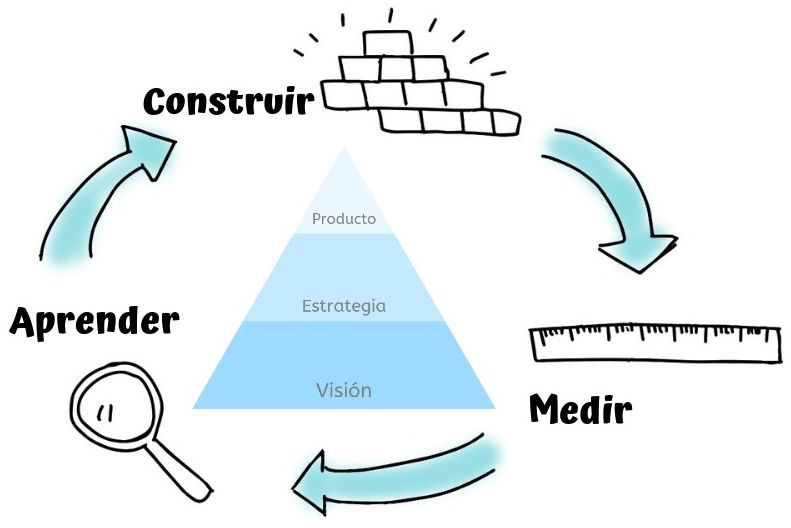
Ahora bien, existen tres componentes claves que permiten alcanzar los objetivos dentro de Lean startup. Imaginemos que vamos manejando al trabajo, estamos decididos en llegar y no nos damos por vencidos debido a un desvío o porque tomamos una ruta equivocada. De la misma manera Lean Startup tiene una brújula de hacia dónde se quiere llegar, a crear un negocio que cambie la vida de muchas personas y que sea próspero para todos, esto es llamado Visión.
Para lograr esa visión, Lean startup emplea una estrategia, la cual incluye el modelo de negocio, el roadmap del producto, un punto de vista de la competencia y los socios, e ideas sobre quiénes serán los clientes.
Gracias a la visión y estrategia se llega al punto final, el producto. El producto cambia constantemente en un proceso de optimización llamado Afinación del Motor. Con menos frecuencia la estrategia sufre cambios, a estos cambios se le llama pivote, la visión muy rara vez cambia porque se está totalmente enfocado en conseguir los principios establecidos en la visión.
Visión, producto, estrategia
Una startup es un portafolio de actividades. Muchas cosas suceden simultáneamente; el motor está corriendo, consiguiendo nuevos clientes y atendiendo a los existentes; se afina el motor, tratando de mejorar el producto, marketing y operaciones; se está dirigiendo con el volante Construir-Medir-Aprender, dónde se decide si es necesario un cambio en la estrategia y cuándo hacerlo (pivotar).
Aunque hablamos de dos importantes ciclos de retroalimentación, Motor de crecimiento y Construir-Medir-Aprender. Este último tiene una gran importancia e influye poderosamente al primero gracias al aprendizaje validado que se obtiene. A medida que vamos aprendiendo con el ciclo de Construir-Medir-Aprender, podremos hacer cambios en el motor, podemos definir con mejor seguridad que tipo de motor necesitamos y que mejoras debemos hacer a este motor para acelerar el crecimiento, y por supuesto, que dirección tomar.
El motor de crecimiento realmente es tu producto o servicio, y depende de las decisiones tomadas en tu estrategia, la cual a su vez está subordinada por el ciclo Construir-Medir-Aprender, y la última parte, la visión de tu startup, es la base de todos estos componentes. Podríamos decir que la pirámide de los tres componentes claves para una startup se encuentra en el centro del ciclo Construir-Medir-Aprender, los resultados de este ciclo influyen en cambios en el producto y en la estrategia, pero como mencionamos antes, muy rara vez influirá en la visión, pero no se descarta que su influencia en la visión pueda suceder.
Un diagrama representando esta relación sería el siguiente:
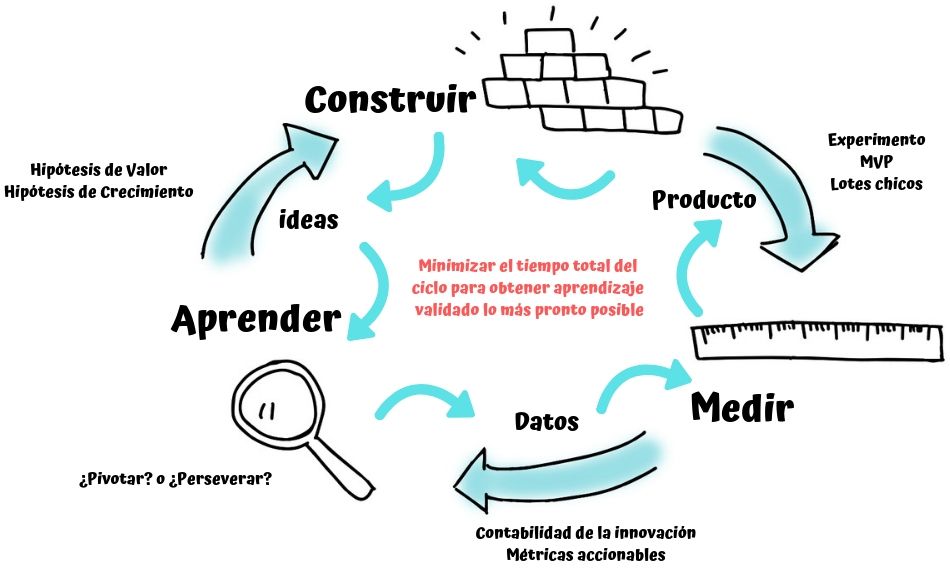
Veamos con más detalle este grandioso ciclo de aprendizaje validado, recuerda que decimos que es un aprendizaje validado porque nos permite saber lo que el cliente realmente quiere y está dispuesto a pagar por ello.
En la imagen de arriba vemos que tenemos flechas en ambas direcciones, esto es así porque el orden en que se ejecutan las tres etapas es inverso a su planeación, describamos un poco estas etapas, empezaremos con la planeación, que es lo primero que haríamos antes de ejecutar nuestro plan. Una startup transforma ideas en productos, estas ideas u oportunidades de negocio nos permite definir nuestra visión en dos partes, esto sería nuestro primer aprendizaje base:
Hipótesis de valor, que nos permite probar que nuestro producto es de valor para nuestros clientes potenciales.
Hipótesis de crecimiento que nos revela de que manera nuevos clientes pueden fácilmente descubrir los beneficios del producto y expandir nuestro alcance.
Luego teniendo la definición de nuestras hipótesis, ahora podemos utilizar innovación contable para saber que es lo que específicamente necesitamos medir para que en la ejecución podamos determinar si estamos obteniendo aprendizaje validado.
Posteriormente basado en las dos etapas anteriores sabremos definir lo que se va a construir, es decir, que experimento correr y obtener los datos necesarios para saber si vamos por buen camino (perseverar) o necesitamos pivotar.
Ya que tenemos el plan de nuestra iteración, es el momento de la ejecución, es decir, Construir, Medir y Aprender.
Los productos que se construyen en una startup son nada más que experimentos, experimentos realizados lo más pronto y lo más ágil posible, y lo ideal es realizar avances pequeños (lotes chicos) para aprender rápidamente cómo construir un negocio sustentable.
Muchas iteraciones de este ciclo serán experimentos fallidos y también habrá experimentos exitosos, pero esto es bueno, una Startup necesita de los aciertos y de los errores lo más temprano posible para conseguir sus objetivos.
Estos aciertos y errores son medidos antes de obtener nuestro aprendizaje, pero esta medición es muy diferente a las métricas tradicionales, es por eso que se le llama innovación contable.
Ahora que terminamos de construir nuestro experimento, lo pusimos a prueba con clientes potenciales y obtuvimos las métricas necesarias en nuestra iteración, es hora de Aprender. Ya que tenemos nuestro aprendizaje validado, sabremos si pivotar o perseverar y de nuevo planeamos la siguiente iteración para poder ejecutar de nuevo este ciclo.
NOTA: Solo soy aprendiz de Lean Startup, es un tema del que estoy aprendiendo muchísimo y del cual plasmo ese aprendizaje a través de esta publicación, una publicación que espero les sea de gran utilidad.
“Event loop”, tal vez lo has escuchado. Esto es porque javascript tiene modelo de ejecución de código donde utiliza un ciclo de eventos (event loop), que una vez entendiendo su funcionamiento, se puede crear código mucho más eficiente, y resolver problemas rápidamente, que a simple vista no son tan obvios. Es la base de la concurrencia y el asincronismo.
Para comenzar:
Javascript se ejecuta en un solo hilo de ejecución, como se ejecuta un solo hilo, su ejecución es secuencial, no es como JAVA donde se pueden lanzar otros hilos.
Existen ambientes huéspedes donde se ejecuta javascript que tienen su propia API, ejemplo:
Navegador web
Node.js
Este funcionamiento secuencial es el mismo, no cambia por estar relacionado con un ambiente huésped.
La concurrencia se logra a través de invocaciones asíncronas a la API del ambiente huésped, esto evita que el funcionamiento se bloquee y provoque lentitud de las aplicaciones.
Elementos para la concurrencia
Veamos con más detalle los elementos que hacen funcionar Javascript en los ambientes huéspedes.
Call Stack – Pila de ejecuciones
Callback Queue – Cola de retrollamadas, tambien llamado Task Queue
Event Loop – Ciclo de eventos
Host Environment – Funcionalidad del ambiente huésped
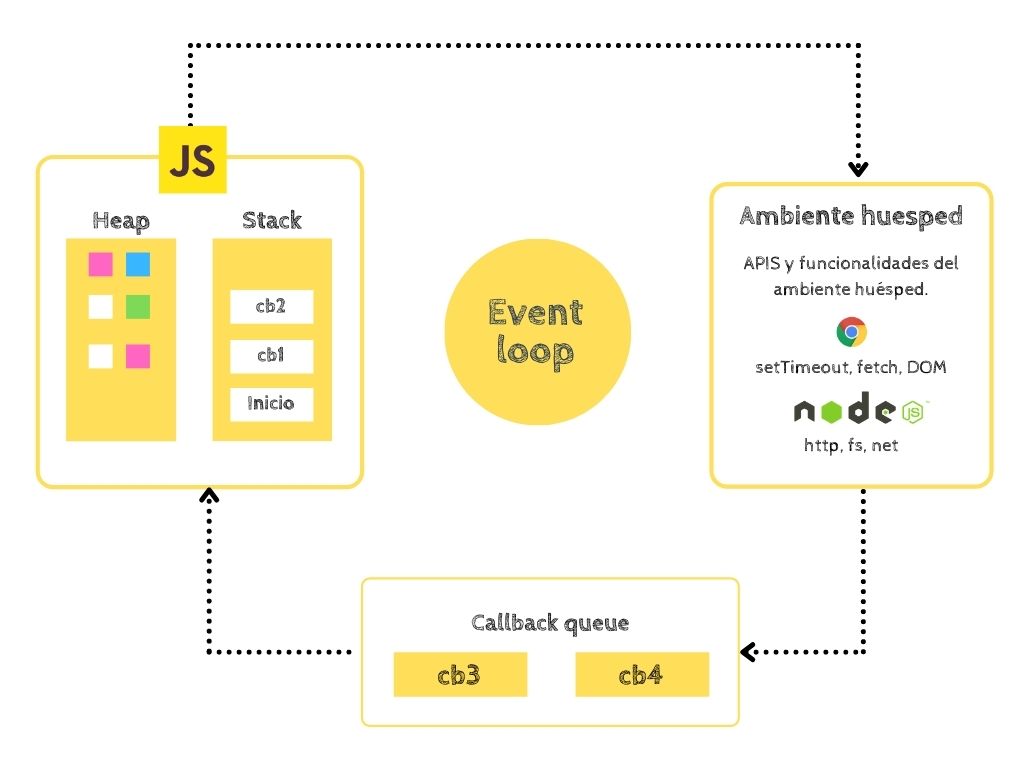
Event loop, ciclo de eventos javascript
Calls Stack, heap y motor de javascript
Del lado izquierdo tenemos al motor de javascript, este motor se encarga de ejecutar nuestro código. A veces es llamado máquina virtual, porque se encarga de interpretar nuestro código a lenguaje máquina y ejecutarlo. Solo puede ejecutar una línea de código a la vez. Tiene un Heap para guardar objetos y demás datos en memoria que el código pueda generar.
Pero también tenemos una Pila de llamadas (Call Stack). Los elementos de la pila son objetos y datos de memoria, pero tienen una estructura especifica. Tienen un orden y el último elemento en entrar es el primero en salir, se le llama LIFO (Last-in, First-out).
Cada elemento de la pila es un trozo de código Javascript y guarda las referencias del contexto y variables utilizadas. La pila ejecuta el trozo de código en turno hasta quedar vacía.
Callbacks Queue
Abajo tenemos Callbacks Queue, es una estructura de datos y guarda pedazos de código que el motor de javascript puede ejecutar. Es una cola, y como la cola de las tortillas el primero en formarse, es el primero en salir (FIFO, First-in, First-out).
Un callback, es una función que se pasa por parámetro a otra, de tal manera que esta última ejecuta el callback en un punto determinado, cuando las condiciones y/o los datos cumplen una cierta regla de invocación.
Event loop
Event Loop, este elemento nos permite mover la siguiente callback del Callbacks Queue al Call Stack. Como es un ciclo, en cada iteración toma un solo callback.
Ambiente huésped
Del lado derecho tenemos El ambiente huésped, el ambiente huésped es el lugar donde corremos Javascript, los más comunes son el Navegador web y Node.js. Las tareas que ejecuta el ambiente huésped son independientes de los demás componentes. En el navegador web tiene sus propias API como fetch, setTimeout, alert. Node.js también cuenta con su propia API como net, path, crypto.
¿Cómo es posible?, ¿Y la concurrencia? ¿Puedo hacer muchas cosas a la vez en un sitio web?
Todo el trabajo de poner un temporizador, renderizar contenido como texto, imágenes, animaciones, o ver videos, están a cargo del ambiente huesped. Lo que pasa es que las APIs del navegador web generan callbacks cuando su tarea ya está completada y los agrega al Callbacks Queue para que el event loop las tome y las mueva al Callstack.
Javascript se comunica con el ambiente huésped a través de su API, mas adelante vamos a utilizar un ejemplo basado en el diagrama de arriba, donde se utiliza window.setTimeout, la cual es una función del navegador web.
Concurrencia
Inicio es la función principal, con la que se inicia el proceso de ejecución en el call stack. Dentro de inicio tenemos cuatro setTimeout de dos segundos. La función setTimeout es propia del ambiente huésped, y a los cuatro setTimeouts le pasamos un callback, estos son, cb1, cb2, cb3 y cb4.
Los temporizadores setTimeout se ejecutan en la parte de la funcionalidad del ambiente huésped dejando tiempo de ejecución para el call stack. He aquí la concurrencia, mientras el ambiente huésped ejecuta un temporizador, el call stack puede continuar ejecutando código.
Después de los primeros dos segundos, el ambiente huésped, a través del primer setTimeout pasa cb1al callback queue, pero durante estos dos segundos se pueden realizar otras operaciones en el ambiente huésped, en el caso del navegador, un ejemplo seria que el usuario puede seguir escribiendo dentro de un textarea. De nuevo, he aquí la concurrencia.
Tras el primer setTimeout, el segundo setTimeout pasa cb2al callback queue y así sucesivamente hasta el cb4. Mientras los callbacks se pasan al callback queue. El event loop nunca deja de funcionar, por lo que en alguna iteración el event Loop pasa cb1al call stack y se empieza a ejecutar el código de cb1y esto mismo sucede con cb2, cb3 y cb4.
Event loop en acción
Aquí abajo esta el ejemplo del que hablamos, el temporizador genera los callbacks en el orden que aparecen los setTimeouts más dos segundos. El Event Loop toma un callback en cada iteración, por lo que cada cb de setTimeout se invocan uno después del otro, y no exactamente después de dos segundos, pues entre que se posicionan los callbacks en la cola y se mueven al callstack de ejecución transcurre más tiempo. Esto sin contar el tiempo que trascurre entre cada invocación de setTimeout.
Si en los cuatro callbacks se indica el mismo tiempo en milisegundos. Presiona el botón RERUN, Te darás cuenta de que los tiempos no son iguales y que pueden pasar más de dos segundos.
Conclusión
Las APIs huéspedes reciben callbacks que deben insertar en la callback queue cuando el trabajo que se les encomienda esta hecho, por ejemplo un callback de una petición ajax se pasa a la callback queue solo cuando la petición ya obtuvo la respuesta. En el ejemplo que describimos arriba con setTimeout, cuando pasan dos segundos, se inserta el callback al callback queue.
Mientras el ambiente huésped realiza sus tareas, en este caso, los demás temporizadores, el call stack de ejecución de javascript puede ejecutar el código que el event loop le puede pasar desde el callback queue.
El Event loop es un ciclo infinito que mientras existan callbacks en el callback queue, pasara cada callback, uno por uno, al call stack.
El call stack no puede ejecutar más de un código a la vez, va ejecutando desde el último elemento hasta el primero, en nuestro caso hasta la terminación de la función inicio que dio origen a todo el proceso. Es una estructura de datos tipo Pila.
Gracias a que los callbacks se ejecutan hasta que un trabajo específico esté terminado, proporciona una manera asíncrona de ejecutar tareas. Las tareas pueden realizarse en el ambiente huésped sin afectar la ejecución del call stack. En la pila solo se ejecuta código que recibe el resultado de las tareas realizadas por el ambiente huésped.
Redux es un contenedor predecible del estado de aplicaciones JavaScript.
Te ayuda a escribir aplicaciones que se comportan de manera consistente, corren en distintos ambientes (cliente, servidor y nativo), y son fáciles de probar. Además de eso, provee una gran experiencia de desarrollo, gracias a edición en vivo combinado con un depurador sobre una línea de tiempo.
redux.org
Te permite controlar el flujo de datos de una aplicación Javascript, este flujo de los datos funciona en una sola dirección. Por esta única dirección es mucho más fácil controlar las mutaciones y operaciones asíncronas.
Redux es parecido a flux, de hecho está basado en flux
En el estado de una aplicación, principalmente en aplicaciones SPA, esto es muy importante, porque las aplicaciones web modernas tienen gran complejidad de operaciones asíncronas. Además de controlar el estado entre los componentes.
¿Qué problemas puedo mitigar con Redux?
En el ejemplo de aplicaciones web, estas necesitan controlar peticiones a servidores, obtener datos y controlar el estado en el cliente. Aun cuando estos datos no han sido guardados en el servidor.
Estas aplicaciones modernas requieren de un control complejo y por eso nuevos patrones de arquitectura como Redux y flux nacen para hacer el desarrollo más productivo.
Las mutaciones de objetos son difíciles de manejar y más a escalas medianas y grandes. Se comienza a perder el control de los datos, este flujo de datos generan comportamiento no deseados. Mala información desplegada al usuario y código que es muy difícil de mantener.
Sin contar cosas más elevadas como tu salud y causa de estrés por el esfuerzo en arreglar estas inconsistencias, te hace perder tiempo para mantener la aplicación funcionando correctamente. Por si fuera poco afectas a tus usuarios porque ellos obtienen información incorrecta y pierden su tiempo al utilizar esa información.
¿Qué decir de las operaciones asíncronas? Bueno, prácticamente pasa lo mismo o aún peor. Porque en una operación asíncrona no sabes cuando obtendrás el resultado y además normalmente vienen acompañadas con el deseo de hacer modificaciones al estado de la aplicación.
Un ejemplo común es el control de los datos de tu aplicación con cualquier frawework front-end de componentes visuales.
¿De qué está hecho Redux? Tres elementos
Store. El store es un objeto donde guardas toda la información del estado, es como el modelo de una aplicación, con la excepción que no lo puedes modificar directamente, es necesario disparar una acción para modificar el estado.
Actions. Son el medio por el cual indicas que quieres realizar una modificación en el estado, es un mensaje o notificación liviana. Solo enviando la información necesaria para realizar el cambio.
Reducers. Son las funciones que realizan el cambio en el estado o store, lo que hacen internamente es crear un nuevo estado con la información actualizada, de tal manera que los cambios se reflejan inmediatamente en la aplicación. Los reducers son funciones puras, es decir, sin efectos colaterales, no mutan el estado, sino que crean uno con información nueva.
¿Qué principios debo seguir? Tres principios
Un único Store para representar el estado de toda la aplicación. Tener una sola fuente de datos para toda tu aplicación permite tener centralizada la información, evita problemas de comunicación entre componentes para desplegar los datos, fácil de depurar y menos tiempo agregando funcionalidad o detectando errores.
Estado de solo lectura. Esto permite tener el control de cambios y evitar un relajo entre los diferentes componentes de tu aplicación, ni los componentes, ni peticiones ajax pueden modificar directamente el Estado (state) de tu aplicación, esto quiere decir que si quieres actualizar tu estado, debes hacerlo a través de actions, de esta manera redux se encarga de realizar las actualizaciones de manera estricta y en el orden que le corresponden.
Los cambios solo se hacen con funciones puras. Al realizar los cambios con funciones puras, lo que realmente se hace es crear un nuevo objeto con la información actualizada, estas funciones puras son los reducers y no mutan el estado, al no mutar el estado, se evitan problemas de control, datos incorrectos, mal comportamiento y errores, también permite que la depuración sea más fácil. Puedes dividir los reducer en varios archivos diferentes y las pruebas unitarias son fáciles de implementar. Los reducers son funciones puras que toman el estado anterior y una acción, y devuelven un nuevo estado.
Otras arquitecturas como MVC (Modelo, Vista, Controlador), los cambios pueden existir en ambas direcciones, es decir, la vista puede cambiar el estado, el modelo lo podría modificar y también el controlador. Todos estos cambios necesitan estar sincronizados en varias partes de una aplicación para evitar inconsistencias, lamentablemente este problema de inconsistencia se vuelve muy difícil y tedioso de resolver.
Lo anterior no sucede con Redux.
¿Cómo funciona? Mi primer estado predecible con Redux
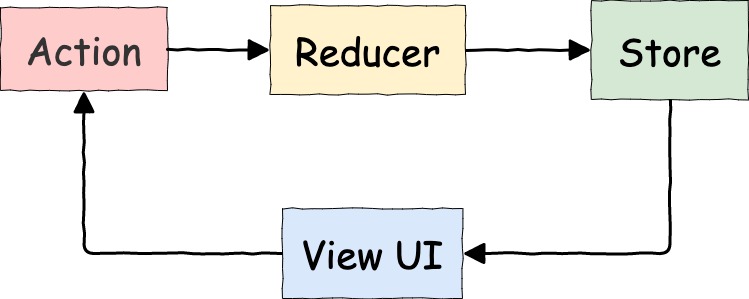
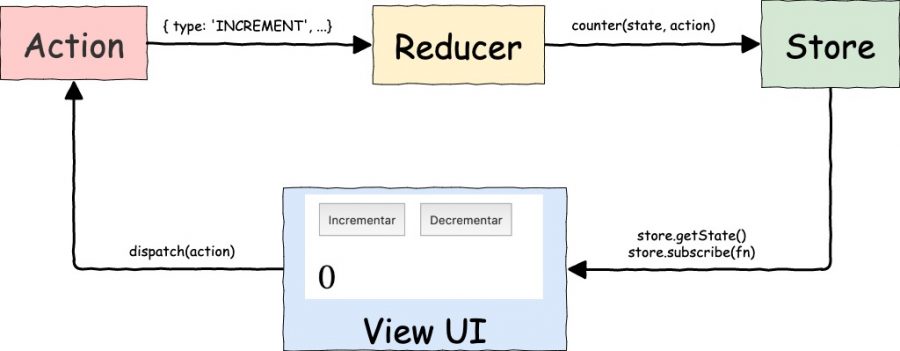
Primero veamos el flujo de una sola dirección de redux:
Redux: flujo de control una sola dirección
Ahora un ejemplo concreto para saber de que estamos hablando, el control de un contador:
Si quieres probar este ejemplo en tu máquina recuerda insertar o importar la librería Redux. En este ejemplo podemos ver el funcionamiento de Redux, cada vez que se da clic sobre los botones de incrementar y decrementar, el contador se incrementa y decrementa.
Si ahora nos vamos al código JS, podremos ver que solo tenemos una función llamada counter, esta función es un reducer y es una función pura, sin efectos colaterales.
Luego vemos que como parámetros recibe un state y un action, cuando creamos nuestro Store con Redux, estas funciones reducer son utilizadas para modificar el State.
Normalmente, el state, reducer y action son definidos en puntos diferentes, y pueden ser organizados en varios archivos y carpetas dependiendo de la necesidad de la aplicación, toda esta organización tiene la finalidad de tener un código limpio y separar funcionalidades. En este caso sencillo no es necesario, en un solo archivo tenemos todo.
State
Nuestro state es solo un valor numérico, el cual se va a incrementar o decrementar con los botones que están en la página, normalmente el state es un objeto literal o un array literal, pero en nuestro caso solo necesitamos un número. Su definición podría estar en otro archivo, sin embargo, para este ejemplo no es necesario, lo agregamos como valor por defecto del parámetro state.
functioncounter(state=0,action){...
Actions
Si seguimos revisando nuestro código, veremos unos cuantas condiciones que revisa el valor del parámetro action y dependiendo de la acción, se ejecuta alguna operación, en nuestro caso son las operaciones INCREMENTAR o DECREMENTAR.
Los actions no son más que objetos literales como los siguientes:
Los reducer revisan esos actions, en nuestro ejemplo:
if (action.type ==='INCREMENTAR') {returnstate+1;}if (action.type ==='DECREMENTAR') {returnstate-1;}
Con todo esto ya tenemos nuestro State y su estado inicial en caso de no estar definido, también nuestra primer reducer, counter, y nuestros primeros actions INCREMENTAR y DECREMENTAR.
Store
Es el momento de crear nuestro Store, utilizando la librería redux esto es muy fácil:
const store = Redux.createStore(counter);
Con la anterior línea, Redux crea un Store para controlar el estado de nuestra aplicación. Internamente, un Store es un Patrón observador que utiliza un Singleton para el State y expone los siguientes métodos principales:
store.getState()
store.subscribe(listener)
store.dispatch(action)
store.getState() te permite obtener el estado actual de tu aplicación.
store.subscribe(listener) ejecuta la función listener (u observador), cada vez que el store es actualizado.
store.dispatch(action) pide actualizar el estado, esta modificación no es directa, siempre se realiza a través de un action y se ejecuta con un reducer.
Reaccionar a cambios del state
Luego creamos una función render, para que se ejecute cada vez que el State de tu aplicación cambie.
Aquí te preguntarás, ¿Cómo es posible que esa línea imprima 0 en la pantalla?, pues internamente el store invoca un dispatch con un action vacío store.dispatch({}), esto invoca nuestra función reducer y al no encontrar ninguna acción, entonces regresa el estado inicial 0.
Luego nos subscribimos a store para escuchar u observar el State cada vez que se actualice y poder ejecutar la función render().
store.subscribe(render);
Esta línea permite que cuando demos clic en los botones de incrementar y decrementar, se imprima el nuevo valor en la página volviendo a renderizar su contenido.
Ejecutar dispatch a través de eventos del DOM
Y por último agregamos dos listeners correspondientes a los botones de incrementar y decrementar, cada botón realiza una invocación dispatch para modificar el estado.
Al fin tenemos el flujo de datos de nuestro sencillo ejemplo usando Redux, en general los componentes que forman a una aplicación que utiliza Redux son los siguientes:
Redux: flujo de control completo
Conclusiones
Podemos notar el flujo en una sola dirección desde la vista con los actions dispatch(action), luego los reducers counter(prevState, action) para modificar el store y este último manda la información a través de subscribe(render) y getState().
Redux como ya se mencionó en párrafos anteriores, nos proporciona:
El conocimiento en todo momento del estado de nuestra aplicación y en cualquier parte de la aplicación con mucha facilidad.
Fácil organización, con actions, reducer y store, haciendo cambios en una sola dirección, además puedes separar tus actions, reducer y el store en varios archivos.
Fácil de mantener, debido a su organización y su único store, mantener su funcionamiento y agregar nuevas funcionalidades es muy sencillo.
Tiene muy buena documentación, su comunidad es grande y tiene su propia herramienta para debuguear
Todos los puntos anteriores hacen que sea fácil de hacer pruebas unitarias.
Y lo más importante, te ahorra tiempo, dinero y esfuerzo xD.
El mundo es un entorno cambiante, los mercados, las industrias, las personas, los usuarios, por consiguiente también los problemas, es aquí donde entra en escena Scrum. Por esta razón, es necesario una perspectiva que nos permita conocer y aprender del problema. Conocer y aprender nos da la capacidad de inspeccionar para poder realizar adaptaciones a la solución de tal manera que disminuya la incertidumbre.
Scrum es un framework ágil que sirve para construir productos que generan un alto valor e impacto para el negocio del cliente y al mismo tiempo se construye la solución con el mínimo esfuerzo.
El beneficio de scrum es darnos la habilidad de adaptarse al cambio sin perder la estabilidad de la solución, gracias al desarrollo sustentable implementado. ¿Qué queremos decir con sustentable? Significa que la solución conserva su estabilidad aun cuando iterativamente lo incrementamos. La calidad del producto influye considerablemente en la sustentabilidad de la solución.
El primer paso es alinear ciertos principios y valores. De tal manera que en conjunto sean la masa rocosa en la que se pueda edificar un castillo y no la masa de arena en la que solo nos permita construir una casa y a la primera llovizna se derrumbe.
Cuando hablamos de principios y valores estamos hablando de las relaciones interpersonales. Esto es importante porque las personas son los individuos que en conjunto forma un equipo para crear los productos, aplicaciones y sistemas computacionales que otros individuos van a utilizar. Estas mismas personas son las que forman empresas y organizaciones.
Individuos e interacciones sobre procesos y herramientas.
Es por eso que los valores en los que se basa Scrum giran alrededor de principios que promueven productivas interacciones entre individuos:
Coraje
Enfoque
Compromiso
Respeto
Apertura (franqueza, actitud abierta y receptiva)
Los valores de Scrum están basados en varios principios básicos del ser humano, no son principios difíciles, es sentido común, busca en tu interior y verás que esos principios siempre están latentes en menor o mayor medida, cada persona es diferente, pero estos principios siempre están ahí:
Honestidad
Justicia
Integridad
Amor
El uso exitoso de Scrum depende de que las personas lleguen a ser más virtuosas en la convivencia con estos cinco valores. Las personas se comprometen de manera personal a alcanzar las metas del equipo scrum. Los miembros del equipo Scrum tiene el coraje para hacer bien las cosas y para trabajar en los problemas difíciles. Todos se enfocan en el trabajo del sprint y en las metas del equipo Scrum. El equipo Scrum y sus interesados acuerdan estar abiertos a todo el trabajo y a los desafíos que se les presenta al realizar su trabajo. Los miembros del equipo Scrum se respetan entre sí para ser personas capaces e independientes.
Respeto
Los miembros del equipo Scrum se respetan entre sí para ser personas capaces e independientes. Pero ¿Qué quiere decir respetarse?, para mí el respeto es preocuparse por la otra persona, esta preocupación es resultado de apreciar a los integrantes de tu equipo y este aprecio viene del amor, sí, suena cursi, pero es verdad, piénsalo.
Dado que respetas a los demás integrantes del equipo, estás totalmente dispuesto a ayudar a mejorar, opinar de manera constructiva y a respetar las opiniones de los demás. Este respeto recíproco se convierte en una gran confianza para que cada individuo se convierta en una persona capaz e independiente, cada individuo realizará su mayor esfuerzo debido a su integridad y respeto a los demás, lo que provoca un ciclo infinito de buenas intenciones.
Coraje
Porque tienes aprecio a tu equipo y a las metas propuestas, porque tu integridad es fuerte y sabes quien eres para el equipo, tienes el coraje de alzar la mano cuando algo esté bloqueando o disminuyendo la productividad. Tienes el coraje de opinar y hablar de mejoras dentro del equipo y también dentro de la organización misma si es necesario.
Enfoque
Cada miembro del equipo está consciente que para ser ágil y ayudar al equipo a realizar su trabajo es necesario enfocarse en el objetivo definido en cada sprint. Así evitamos desviarnos de lo que se quiere lograr en nuestras actividades diarias. Esto nos permite NO malgastar nuestro tiempo en cosas que no son importantes para el objetivo actual y acelerar el desarrollo de la solución.
Compromiso
Porque cada integrante del equipo tiene una integridad latente y comparten una gran honestidad y respeto. Entonces los miembros se comprometen de manera personal a alcanzar el objetivo del equipo Scrum porque saben perfectamente que ese compromiso es beneficioso para todos, porque les permitirá eliminar la frustración individual y del equipo.
No es estricto cumplir con cada detalle en específico de las tareas en un sprint, mientras no afecten al logro del objetivo se puede negociar el alcance. Pero cada integrante realiza con gusto su mayor esfuerzo, trabajando con transparencia y respeto mutuo. Si no se cumple totalmente lo esperado, existen eventos durante y después de un sprint que nos ayudan a mejorar nuestro alcance sin afectar el objetivo del sprint.
Apertura (franqueza, actitud abierta y receptiva)
Porque aprecias a tu equipo, eres honesto y te guías por la justicia. Estás abierto a opiniones, abierto al trabajo que se necesita hacer, al respeto mutuo y la honestidad o transparencia. A inspeccionarte a ti mismo y adaptarte para que el equipo Scrum sobrepase todo el trabajo y desafíos del proyecto.
Teoría de control de proceso empírico de Scrum
Ahora bien, dado que el entorno en que se trabaja es cambiante, scrum también se basa en la teoría de control de procesos empírico. Según la guía de Scrum:
El empirismo asegura que el conocimiento procede de la experiencia y de tomar decisiones basándose en lo que se conoce. Scrum emplea un enfoque iterativo e incremental para optimizar la predictibilidad y el control del riesgo.
El empirismo de Scrum se construye con tres pilares:
Transparencia
Inspección
Adaptación
Anotación importante, los cimientos o la masa rocosa de estos tres pilares son los cinco valores de Scrum.
Pilares de scrum, transparencia, inspección y adaptación
Haciendo una analogía rápida con un espejo. Si nos paramos enfrente del espejo, pero este tiene manchas que no nos permiten vernos claramente, quiere decir que no es transparente. Lo cual provoca que si quiero peinarme, no podre inspeccionar mi cabello, dado que no logro observar bien mi cabello no podre adaptarlo para que quede bien arreglado y peor aún, no sabré el resultado final de mi peinado.
Ahora, si el espejo está completamente limpio y transparente, este espejo seria Scrum (bien implementado claro), podre inspeccionar el estado de mi cabello y podré adaptarlo peinándome a una velocidad superior que si el espejo tuviera manchas, podre peinarme correctamente y podre contemplar el resultado final ("Mi .¨Vbñ´Vcabello bien peinado... jajaja xD).
Transparencia
Todos los aspectos importantes del proceso deben ser visibles para aquellos que son responsables del resultado.
De esta manera cada integrante de un equipo scrum tiene los datos y las herramientas necesarias para conocer todos los aspectos de lo que se va a construir y/o se está construyendo.
Inspección
La inspección no se puede dar si no hay transparencia, la inspección es visualizar e identificar los puntos de mejoras u errores de tal manera que se conoce y aprende profundamente sobre el problema a resolver. Este pilar provoca el aprendizaje.
Adaptación
Debido a la transparencia del proceso y al aprendizaje con la inspección, se puede mejorar y tomar las acciones necesarias para aumentar el valor e impacto de la solución al mismo tiempo que se reducen riesgos y también se mitigan desviaciones de los objetivos deseados. En conclusión se adapta.
Roles de un Scrum Team
El framework scrum define tres roles:
Product Owner responsable de maximizar el valor del producto/servicio que se va a construir. Administra el product backlog.
Desarrolla y comunica explícitamente el objetivo del producto
Crea y comunica claramente los elementos del product backlog
Ordenar los elementos del product backlog
Asegurarse de que el producto backlog sea transparente, visible y que se entienda.
Scrum Master, ayuda a todo el equipo a entender el framework scrum con la teoría, reglas, valores y prácticas. Es un verdadero líder que sirve a los developers, product owner y a toda la organización.
Developers, son las personas que van a construir el producto y/o servicio. Sus responsabilidades principales son:
Crear un plan para el sprint, esto es el sprint backlog
Inculcar calidad al adherirse a una definición de terminado (DoD)
Adaptar su plan cada día hacia el objetivo del sprint
Responsabilizarse mutuamente como profesionales
Estos tres roles en conjunto forman el scrum team. Dentro del scrum team no existen las jerarquías ni tampoco se dividen en sub equipos. También el scrum team son multifuncionales, esto quiere decir que en conjunto tiene todas las habilidades necesarias para crear valor en cada sprint. Pueden compartir las habilidades y adquirirlas según se vaya necesitando.
El tamaño del scrum team debe ser lo suficientemente pequeño para facilitar la agilidad, pero lo suficientemente grande para generar el suficiente valor en cada sprint, normalmente 10 personas o menos. Si es necesario un equipo más grande, entonces se debe considerar crear varios scrum teams enfocados en el mismo producto. En consecuencia deben compartir el mismo objetivo del producto, product backlog y product owner.
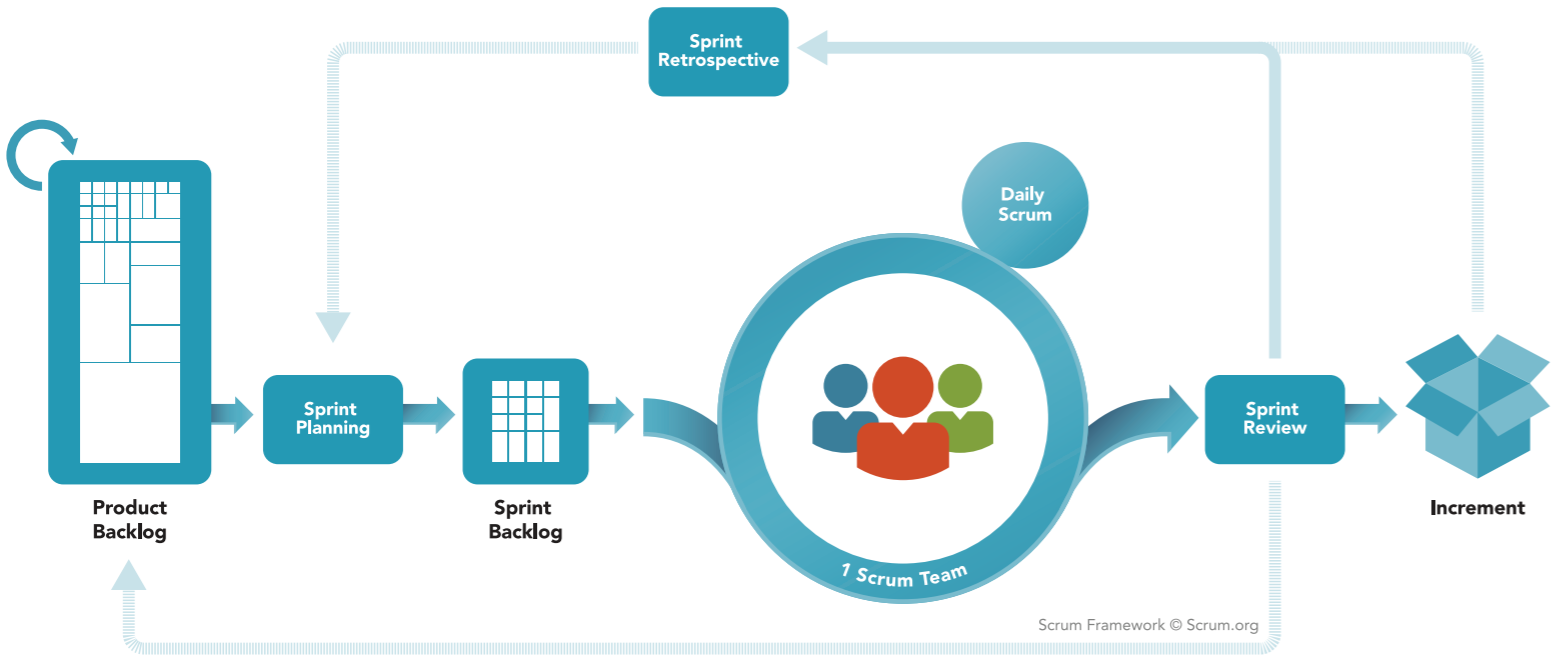
Eventos de scrum
Cada uno de los pilares anteriores se viven en los Eventos de Scrum, nos ayudan a la inspección y adaptación de los artefactos, es decir, provocan el aprendizaje y la mejora continua, pero para eso cada evento y artefacto debe tener total transparencia. Así también cada uno de los valores de scrum se viven en todo el proceso, como se manifestó antes, son los cimientos de los pilares y de scrum.
Saltarse cualquier evento de scrum hace que se pierda una oportunidad para inspeccionar y adaptarse. Además, cumplir con los eventos genera regularidad y minimiza la necesidad de reuniones no definidas en scrum. Como recomendación los eventos deben celebrarse al mismo tiempo y en el mismo lugar para reducir complejidad.
Sprint
Esta palabra significa carrera corta, si, una carrera pequeña que nos permita trabajar en la solución y al mismo tiempo inspeccionar y adaptarnos rápidamente, esto siempre con la transparencia necesaria en todo el equipo. Dentro del sprint suceden los 4 eventos restantes necesarios para lograr el objetivo del producto
Durante un sprint:
No se realizan cambios que pongan en riesgo el objetivo del sprint
La calidad no disminuye
El Product Backlog se refina según sea necesario
El alcance se puede aclarar y renegociar con el Product Owner a medida que se aprende más.
La longitud de un sprint puede ser de un mes o menos, un sprint sigue el principio lean sobre lotes pequeños. Si el sprint es mayor a un mes, se empieza a hacer grande y la complejidad también, lo que provoca un aumento del riesgo. Adicionalmente, al ser un sprint grande el objetivo del sprint puede cambiar y el aprendizaje es mucho más lento porque la retroalimentación no sucede a tiempo.
Un sprint puede cancelarse si el objetivo del sprint se vuelve obsoleto. Solo el Product Owner tiene la autoridad para cancelar el sprint.
Sprint Planning
Aquí se define que se va a hacer en el sprint (objetivo) y como se va a realizar. En la planificación participan todo el equipo scrum de tal manera que se pone en práctica principalmente el foco con el objetivo del sprint y la transparencia del conocimiento de como se va a trabajar.
El sprint planning aborda los siguientes temas:
¿Por qué es valioso este sprint? Resulta en el objetivo del sprint. El product owner propone como el producto puede incrementar su valor y utilidad en el sprint actual.
¿Qué se puede hacer en este sprint? El Product Owner y Developers seleccionan elementos del Producto Backlog para incluirlos en el sprint actual. Pronosticar cuando se puede completar en un sprint es muy difícil, pero cuanto más sepan los Developers sobre su desempeño pasado, su capacidad actual y su Definición de Terminado, más confiados serán en sus pronósticos.
¿Cómo se realizará el trabajo elegido? Los Developers planifican el trabajo necesario para crear un Incremento que cumpla con la Definición de Terminado (DoD). A menudo se hace descomponiendo los elementos seleccionados en piezas más pequeñas que se puedan terminar en un día o menos. La forma de hacerlo queda a criterio de los Developers. Nadie más les dice como convertir los elementos del Product Backlog en Incrementos de valor
El límite de tiempo para el sprint planning es de 8 horas para un sprint de un mes.
El objetivo del sprint, más los elementos seleccionados del product backlog para el sprint actual, más el plan para entregarlos se denominan juntos como Sprint Backlog.
Daily Scrum
Reunión diaria donde se puede ver (transparencia) el avance diario, de tal manera que se pueda inspeccionar y adaptar el progreso actual para lograr el objetivo del sprint. Si el Product Owner y el Scrum Master trabajan continuamente en elementos del Sprint Backlog, entonces ellos participan como Developers.
Los Developers pueden seleccionar la estructura y técnicas que deseen, siempre que su Daily Scrum se centre en el progreso hacia el objetivo del Sprint y produzca un plan viable para el siguiente día de trabajo. Esto genera enfoque y autogestión.
El Daily Scrum es un ciclo de retroalimentación diario que mejora la comunicación, identifica impedimentos, promueve la toma rápida de decisiones y elimina la necesidad de otras reuniones.
El límite de tiempo para el Daily Scrum es de 15 minutos.
Sprint Review
Aquí se revisa el producto o avance, es decir, el artefacto llamado Incremento. De nuevo, esta reunión fomenta la transparencia, inspección y adaptación para el próximo sprint. No es sola una demostración de los avances hasta el momento. Es una oportunidad para detectar adaptaciones.
Para ponerlos más claro, el Sprint Review es un ciclo de retroalimentación al final de cada sprint donde se fomenta la transparencia revisando el Incremento. El Scrum Team en conjunto con los stakeholders inspeccionan los resultados para tomar decisiones de adaptación para lograr el Objetivo del producto, pueden ajustar el Product Backlog si encuentran nuevas oportunidades o cambios importantes.
El límite de tiempo para el Sprint Review es de 4 horas para un sprint de un mes.
Sprint retrospective
Este evento es el que más relación palpable tiene con los pilares scrum en relación con el equipo humano, es donde se toman acciones concretas y se planifica lo que requiere hacer para mejorar la efectividad del equipo y la calidad del trabajo en el próximo sprint.
También es un ciclo de retroalimentación al final del sprint para inspeccionar y adaptar las personas mismas, las interacciones, los procesos y la Definición de Terminado.
El límite de tiempo para el Sprint Retrospective es de 3 horas para un sprint de un mes.
Artefactos de Scrum
Product Backlog (Lista de producto), lista de elementos o requerimientos que hasta el momento se conoce que el producto necesita.
Sprint Backlog (Lista de sprint), son los elementos seleccionados del product backlog para construirse en el sprint actual.
Increment (Incremento), es el producto terminado (hasta el momento) o avance terminado en un determinado sprint.
Más adelante veremos a detalle los roles, los eventos y los artefactos, espero que esta publicación les dé un panorama general de lo que es el Scrum.
Antes de todo, estoy en el proceso de aprendizaje de React y en esta publicación voy a explicar, según mi entendimiento, los métodos del ciclo de vida de un componente con React.
A partir de la versión 16.3 de React se agregaron nuevos métodos del ciclo de vida de un componente para mejorar el rendimiento, buenas practicas y así obtener una mejor calidad de los componentes creados.
Principalmente este cambio es debido a componentes con funcionalidad asíncrona, esto es muy importante porque normalmente el mundo real es asíncrono y los componentes que creamos son utilizados en el mundo real por personas.
Por esta razón también se empiezan a dejar de utilizar los siguientes métodos, esto sucederá a partir de la versión 17 de React:
componentWillMount()
componentWillRecieveProps(nextProps)
componentWillUpdate(nextProps, nextState)
Dado que los anteriores métodos se dejaran de usar en la version 17, los siguientes métodos son los recomendados a utilizar en un componente:
Y para visualizar su relación, aquí está un diagrama de flujo:
Diagrama de los métodos del ciclo de vida de un componente en React
Si observamos el diagrama, el método static getDerivedStateFromProps(nextProps, prevState) sustituye al método deprecado componentWillReceiveProps(nextProps), también parece ser que el método getSnapshotBeforeUpdate(prevProps, prevState) sustituye al método deprecado componentWillUpdate(nextProps, nextState).
Para fines de demostración vamos a crear un componente Padre y otro componente Animal (componente hijo), lo ideal es que el componente Padre maneje todo el state, pero para demostrar el funcionamiento de los métodos ocuparemos algo de state en nuestro componente Animal.
constructor(props)
El constructor es un método de la mayoría de los lenguajes de programación orientada a objetos, y se utiliza para crear la instancia de una clase. En react el constructor se usa para crear la instancia de nuestro componente.
Cabe mencionar que después de la ejecución de este método, nuestro componente aún no se pinta en nuestro navegador, al proceso de pintado, es decir, insertarlo en el DOM, se le llama Montar o Mount en ingles.
Como buena practica de programación es importante ejecutar super() dentro de un constructor para que realice cualquier llamada a constructores padres.
En el caso de react se debe llamar con las props recibidas en el constructor, o sea, super(props), esto nos permite poder acceder a las props a través de this.props dentro del constructor.
El constructor se usa normalmente para las siguietes dos cosas:
Definir el estado local con un componente a través de this.state.
Para enlazar el objeto this(la instancia de nuestro componente) a los métodos que son utilizados en el método render(). Estos métodos son usados como manejadores de eventos
El estado de nuestro componente en el constructor se define así:
Si no defines ningún estado en el constructor, entonces no lo necesitas.
Si se te ocurre definir el state usando las props pasados como parámetros probablemente es mejor definir el state en un componente padre o en la raíz de todos los componentes porque el estado no estará sincronizado con los cambios de las propiedades.
Para enlazar la referencia de la instancia de nuestro componente a los métodos que son utilizados en el método render() y que normalmente son los manejadores de eventos:
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}this.cambiarAnimal=this.cambiarAnimal.bind(this);}cambiarAnimal(){this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Ahora el método this.cambiarAnimal podrá acceder a la instancia de nuestro componente a través de this y así utilizar this.setState() para cambiar el estado.
Existe otra opción para utilizar métodos de nuestra clase como manejadores de eventos, con el uso de funciones flecha (arrow functions).
classPadreextendsReact.Component{constructor(props){super(props);this.state={ src:''}}cambiarAnimal=()=>{this.setState({ src:'Algúna url que apunte a una imagen de un animal'});}render(){return (<div><Animalsrc={this.state.src}/><buttononClick={this.cambiarAnimal}>Cambiar animal</button></div> );}}
Este método es estático, sí, debe tener el modificador static que indica que este método no está enlazado a alguna instancia del componente, sino más bien a su clase. Se invoca después de instanciar un componente y también cuando el componente recibe cambios en las propiedades.
Debe tener siempre un valor de retorno, ya sea un objeto para actualizar el state o null si no se quiere actualizar el state en relación con los nuevos valores de las props recibidas. Es importante saber que este método se ejecuta también cuando un componente padre provoca que el componente hijo sea de nuevo renderizado, por esta razón debes comparar valores anteriores con los nuevos para evitar mandar a actualizar el state cuando no hubo realmente un cambio.
Podemos razonar que este método nos puede servir para mantener sincronizado nuestro state (o solo una parte) con las props pasadas desde un componente padre.
Por el momento en nuestro ejemplo del componente Animal solo visualizaremos los datos y regresaremos null porque no queremos actualizar el estado, además el atributo src de nuestra imagen se actualiza cuando la propiedad src del componente cambia.
Lo siguiente realmente no es necesario, pero para visualizar la ejecución de este método supongamos que dentro de nuestro componente Animal vamos a manejar la url(src) de la imagen del animal en this.state.src, así:
constructor (props) {this.state={ src:props.src};}static getDerivedStateFromProps (nextProps, prevState) {if (prevState.src!==nextProps.src) {// necesario para actualizar la imagen cada vez que cambie this.props.srcreturn{ src:nextProps.src};}returnnull;}render() {return (<imgclassName="cat__img"src={this.state.src} /> );}...
Ahora prueba el código aquí, y revisa los mensajes de la consola, por el momento solo nos estamos enfocando en el constructor(props) y static getDerivedStateFromProps(nextProps, prevState):
render()
Este método es obligatorio en cualquier componente, pues como su nombre lo dice, se utiliza para obtener los elementos finales a visualizar o pintar en el navegador. Debe ser una función pura, es decir, no debe modificar las props, no debe modificar el state ni realizar operaciones del DOM.
Según mi entendimiento, el resultado de este método es utilizado por ReactDOM.render() para insertarlo en el DOM del navegador. Si el componente en cuestión ha sido insertado previamente, solo se muta el DOM lo necesario para reflejar los nuevos cambios, esto quiere decir querender() regresa los objetos necesarios para que en otro lugar sean insertados en el DOM.
Esto se puede comprobar si observas la consola del anterior ejemplo y luego das clic sobre el botón “Cambiar animal” entonces verás que el método render() es ejecutado antes de getSnapshotBeforeUpdate() y componentDidUpdate().
Con esto tengo una duda, ¿En qué momento se modifica el DOM?, yo creo que se modifica el DOM después deReactDOM.render()y antes de quecomponentDidUpdate().
Este método se ejecuta cuando nuestro componente está listo en el DOM, siguiendo el razonamiento explicado en el método render(), se ejecuta después de que React inserte el DOM, y antes del método `render()`. Por eso es útil para realizar llamadas ajax y operaciones con el DOM como agregar eventos y/o modificar elementos internos.
Dentro de este método es seguro cambiar el state, pero si ejecutamos this.setState() provocara que nuestro componente se vuelva a renderizar.
La documentación oficial de React nos advierte tener cuidado con esto, pues puede causar problemas de rendimiento por renderizar nuestro componente varias veces. Sin embargo es necesario para los casos de tomar medidas y posiciones de algunos elementos antes de renderizar, por ejemplo el tamaño y posición de modales y tooltips.
Para ver el uso de este método veamos el siguiente ejemplo, si revisamos la consola veremos que render() se ejecuta dos veces, también si damos clic en el botón Cambiar animal, se nota que de nuevo render() se ejecuta dos veces.
¿Por qué sucede esto?, sucede porque dentro del método componentDidMount() agregamos un escuchador de eventos para la carga de la imagen del animal, al ejecutarse this.onImgLoad().
`this.onImgLoad()` invoca a this.setState() y esta función provoca que el componente se vuelva a renderizar para mostrar las medidas exactas de la imagen cuando se termina de cargar.
shouldComponentUpdate(nextProps, nextState)
En versiones actuales de React, este método se ejecuta para decidir si los cambios en las props o el state merecen que se vuelva a renderizar el componente con estos nuevos datos.
El valor de retorno de esta función es true o false. Si el resultado de este método es true, los métodos render(), getSnapshotBeforeUpdate() y componentDidMount()no se ejecutan.
Recibe como parámetros las nuevos valores pros y del state, con estos valores y los valores actuales de nuestro componente podemos condicionar si es necesario volver a renderizar o no, de esta manera podemos mejorar el rendimiento manualmente.
Si no implementamos este método en nuestro componente, React toma como resultado el valor true, por lo que siempre se volverá a renderizar. El resultado no influye en los componentes hijos, si en un componente padre el resultado es false, esto no impide que componentes hijos necesiten volver a ser renderizados.
Es importante mencionar que en la documentación indica que tal vez en futuras versiones de React, este método no impida un renderizado del componente, o sea, que en un futuro si este método regresa falseaun así se ejecutaran los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
Esto último me deja con un sabor amargo, actualmente este método es un buen lugar para mejorar el rendimiento de nuestro componente porque evitamos el re-renderizado en situaciones que no sean necesarias, pero después en futuras versiones cabe la posibilidad de perder esta habilidad, entonces quiero pensar que deben existir otras maneras de mejorar este caso de rendimiento, ¿Alguien tiene alguna idea?.
Veamos un ejemplo, en el anterior método componentDidMount() mencionamos que agregamos un escuchador de eventos al finalizar la carga de la imagen para poder obtener sus medidas, estás medidas las mostramos en nuestro componente, pero esta el caso de dos imágenes de perros que tiene la misma medida, 128px - 128px, entonces el ancho y el alto de la imagen no cambia, por lo que no es necesario volver a renderizar nuestro componente.
Si cambiamos de entre el perro de raza chihuahua y el perro ladrando, podemos ver en la consola que el último método ejecutado es el shouldComponentUpdate(), como el resultado fue false, no se ejecutaron de nuevo los métodos render(), getSnapshotBeforeUpdate() y componentDidUpdate().
getSnapshotBeforeUpdate(prevProps, prevState)
Este método se ejecuta después de render() y antes de componentDidUpdate(), el valor que regresa la ejecución de este método se convierte en el tercer parámetro llamado snapshot de componentDidUpdate(prevProps, prevState, snapshot), este método debe regresar algún valor o null, si no es así, React nos advertirá con algo parecido al siguiente warning en la consola:
Warning:Animal.getSnapshotBeforeUpdate(): A snapshot value (or null) must be returned. You have returned undefined.
Además recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Este método puede regresar cualquier tipo de valor, por ejemplo puede regresar datos del DOM como cuantos elementos existen en una determinada lista de elementos o la posición del scroll antes de que el componente sea actualizado a través de ReactDOM.render()(si nuestra hipótesis explicada en el método render() es correcta).
Si revisamos el código de getSnapshotBeforeUpdate() y componentDidUpdate() y además revisamos la consola, notaremos que getSnapshotBeforeUpdate() le envía a componentDidUpdate el numero de elementos del DOM que contiene el componente en cuestión, que son 2, el párrafo con las medidas de la imagen y la imagen del animal.
Este método se ejecuta cuando el componente ha sido actualizado totalmente, y es reflejado en el DOM de nuestra aplicación, recibe las props y el state antes de la actualización por lo que es fácil hacer comparaciones con las props y el state actuales a través de this.props y this.state.
Aquí se puede trabajar con el DOM del componente dado que este mismo ha sido actualizado, además se puede realizar operaciones como obtener datos remotos según los cambios de las props o state.
No se ejecuta la primera vez que se usa el método render(), es decir, cuando se monta el componente.
En la consola podemos ver los datos, prevProps, preState, y snapshot, este último tiene el valor 2. También vemos this.props y this.state
componentWillUnmount()
Este método se ejecuta justo antes del que el componente sea desmontado del DOM, es un buen lugar para liberar recursos y memoria. Un ejemplo claro es la eliminación de escuchadores de eventos que ya no se van a necesitar, también se pueden cancelar peticiones remotas que se estén ejecutando actualmente dado que estas seguirán su proceso aún desmontando el componente.
En el ejemplo de abajo se ilustra como se elimina un escuchador de evento load para la carga de la imagen del animal.
El origen de la programación funcional data del año 1936, cuando un matemático llamado Alonzo Church necesitaba resolver un problema complejo, del cual no hablaremos aquí, pero Alonzo creó una solución, el cálculo lambda. De esta forma nació la programación funcional, incluso mucho antes de la primera computadora digital programable y de los primeros programas escritos en ensamblador.
La programación funcional es mucho más antigua que la programación estructurada y la programación orientada a objetos. Te recomiendo también revisar esta información sobre el paradigma de programación funcional.
Sin efectos colaterales
Todo lo que necesitas saber sobre programación funcional es que “No tiene efectos colaterales“, es decir, que sus elementos (funciones) son inmutables.
Lo anterior significa que una función no se mete en lo absoluto con datos que existen fuera de ella, si puede utilizar los datos enviados como parámetros, pero no debe modificarlos, todos los datos deben ser inmutables, ¿Por qué?, pues porque así hacemos las cosas más simples y con menos errores, más adelante tenemos un ejemplo. A este comportamiento se le llama puro.
Sin efectos colaterales nos permite entender todas las demás características de la programación funcional, por mencionar algunas principales:
Funciones puras
Inmutabilidad
Funciones de alto nivel
Funciones currificadas
Recursividad
Menos errores de programación porque no realiza efectos colaterales.
Toda función teniendo ciertos parámetros, cuando se ejecuta, obtendremos un resultado basado en esos parámetros, y si volvemos a utilizar los mismos parametros, entonces la función regresara el mismo valor. Esto es debido a que una función no depende de más datos externos que puedan ser modificados, así tendremos más seguridad y nuestro código se vuelve más entendible.
Bueno, realmente ya explicamos de manera indirecta que es una función pura en los párrafos anteriores, pero veamos una definición formal. Una función pura es la que cumple con estas dos características:
Siempre obtendremos el mismo resultado dado los mismos parámetros de entrada.
No tiene ningún efecto colateral observable, no modifica el estado de los datos externos, por lo que todos los datos deben ser inmutables.
Un ejemplo de como cambiar el nombre de una objeto persona usando primero una función con efector colaterales:
En la anterior función notamos que se cambia objeto jaime, el cual supongamos que es parte del estado de nuestra aplicación, pero puede haber otras funciones que utilicen este objeto, por lo que se puede generar problemas si alguien más espera que la propiedad nombre del objeto siga siendo 'jaime'.
En la versión funcional, cambiarNombre no modifica el objeto jaime, más bien crea un nuevo objeto con la misma edad que jaime y con la propiedad nombre igual a 'Juan', con esto evitamos efectos colaterales por si el objeto jaime es utilizado por otra función u otro programador.
Con esta función sin efecto colateral, nos damos cuenta de que los datos se manejan sin ser modificados, es decir, inmutables, los parámetros persona y nombre nunca fueron cambiados.
Funciones de alto nivel y currificadas
Una función de alto nivel es una función que implementa al menos una de las opciones siguientes:
Recibir como parámetro una o más funciones
Regresar como resultado una función
Un ejemplo muy común usado en nuestro navegador web es agregar escuchadores de eventos:
<buttonid="boton">Soy un botón</button>const boton = document.querySelector('#boton');boton.addEventListener('click',function(){alert('Click sobre el boton');});
En el código pasamos como segundo parámetro del método addEventListener unafunción anónima (sin nombre) que mostrará un alerta al dar click sobre un botón con id igual a ‘botón’. Dado que pasamos por parámetro una función, entonces se dice que es una función de alto nivel.
Otro ejemplo de función de alto nivel lo podemos observar en los métodos de arreglos en Javascript, el código de abajo toma un arreglo de números y crea otro arreglo con los valores aumentados al doble.
La función map retorna un nuevo arreglo, no cambia el arreglo original, por lo que decimos que no existe un efecto colateral.
Las funciones currificadas son funciones de alto nivel que como resultado regresan otra función, de tal manera que el acto de currificar es convertir una función de más de un parámetro en dos o más funciones que reciben parcialmente esos parámetros en dos o más invocaciones currificadas.
Las funciones flecha o arrow functions nos permiten acceder al contexto de los parámetros, es por eso que seguimos teniendo acceso al parámetro a de la primera invocación de summaryCurry. De esta manera cuando se les define un valor, una arrow function puede ver ese valor. Para lograr lo mismo sin funciones flecha se debe utilizar la variable argumentsque existe como variable local dentro de todas las funciones en JavaScript. Para mantener las cosas simples, de momento no veremos como hacerlo con arguments.
Función recursiva
Para crear una función recursiva, primero se define un caso base, luego a través de la división del problema en pedazos más pequeños se encuentra un patrón, este patrón llamado caso recursivo se repite muchas veces, es aquí donde la función se llama así misma y acumula los resultados, la ejecución se detiene hasta llegar a su caso base.
El caso base, el cual permite detener la ejecución de subsecuentes invocaciones de la función recursiva.
El caso recursivo, el cual permite que una función se llame a sí misma hasta llegar al caso base.
El factorial de un número positivo es la multiplicación de ese número por el número inmediato menor y así sucesivamente hasta llegar al número 1, su notación es n!, donde n es un número positivo. Por ejemplo el factorial de 5 es 120, 5! = 5 x 4 x 3 x 2 x 1 = 120.
// caso base:1!=1=1// caso recursivo, ejemplos:2!=2 x 1=2 x 1!3!=3 x 2 x 1=3 x 2!4!=4 x 3 x 2 x 1=4 x 3!5!=5 x 4 x 3 x 2 x 1=5 x 4!
Con estos datos, podemos crear nuestra formula factorial(n) = n * factorial(n-1), lo cual seria nuestro caso recursivo, pero debemos de añadir nuestro caso base para que se detenga, cuando n=1 debemos obtener como resultado 1.
Veamos como quedaría nuestra función recursiva en javascript:
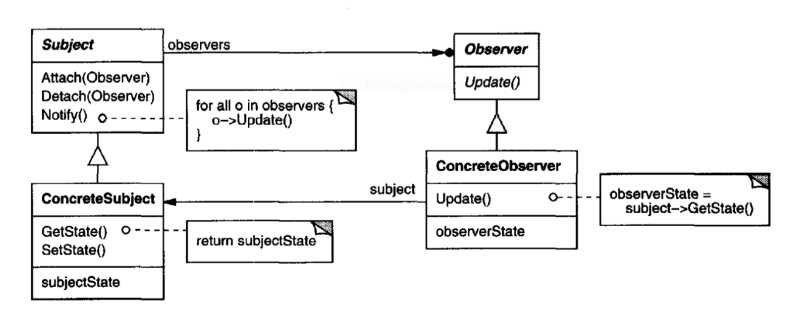
El patrón de diseño observador, define una dependencia de uno a muchos objetos de tal manera que cuando un objeto cambio de estado, todos sus dependientes son notificados y actualizados automáticamente
Del libro “Design patterns: elements of reusable object-oriented software”
Si has utilizado eventos del navegador, como escuchar el evento click sobre un botón, ahí estás utilizando el patrón observador, tu función callback es tu objeto observador y el botón es el sujeto, tu función callback esta interesada en la actividad de dar click sobre el botón.
El Sujeto está compuesto por las siguientes métodos importantes que usaremos en nuestro código javascript:
Una colección de observers
Método attach()
Método detach()
Método notify()
Normalmente un Observador contiene un método update() que el Sujeto utiliza.
Para tener más claro esto, vamos a ver dos ejemplos del patrón observador, el primero será el Observador puro y el segundo en su modo Publicador/Suscriptor.
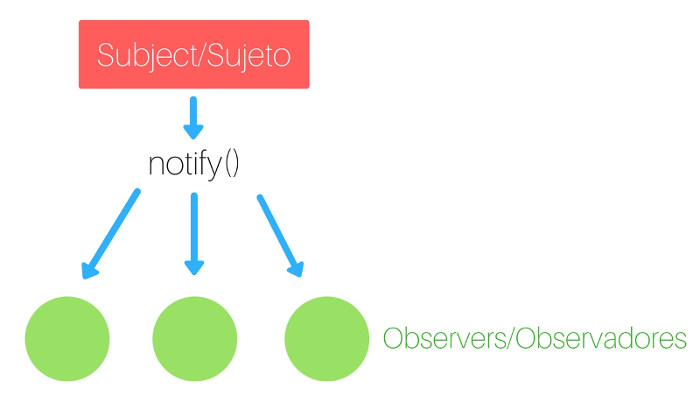
Simplificando el observador
Simplificando el diagrama anterior, el patrón observador funciona así:
Patrón de diseño observador simplificado
Juega con el ejemplo de abajo, y agrega nuevos checkbox, si has agregado más de un nuevo checkbox, podemos notar que cuando damos click en el checkbox ‘Seleccionar‘ todos los demás checkbox nuevos se enteran de esa actividad y se actualizan automáticamente.
Todo esto sin necesidad de estar al pendiente de que el checkbox ‘seleccionar‘ ha cambiado su estado, el encargado de notificar del cambio es el Sujeto y solo si existe algún cambio. Esto es muy eficiente si tienes cientos o miles de checkbox observando ese cambio.
Si das click sobre uno de los checkbox, se ejecuta el método subject.detach(), entonces ese checkbox ya no es un observador, por lo que si ahora activas y desactivas el checkbox seleccionar nunca es notificado sobre el cambio.
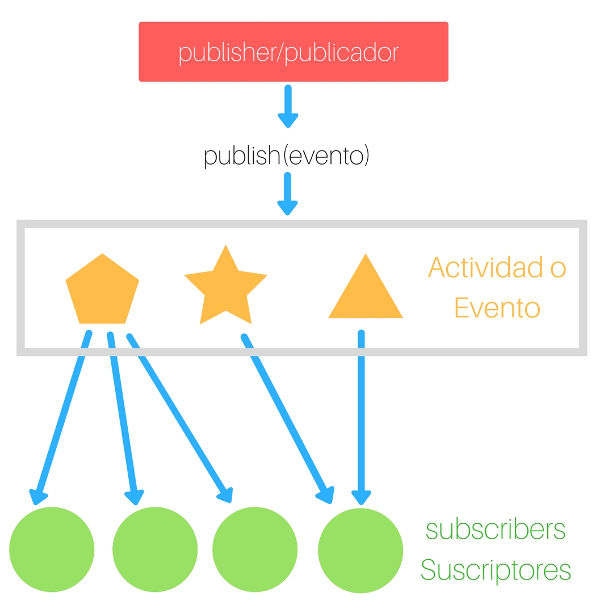
Publicador/suscriptor simple
El patrón de diseño publicador/suscriptor es una variación del observador, en este modo el suscriptor u observador se suscribe a una actividad o evento del publicador o sujeto.
El publicador notifica a todos los objetos suscritos cuando el evento al que están interesados se dispara o publica.
El publicador está compuesto por las siguientes métodos importantes que usaremos en nuestro código javascript:
Una colección de observers o subscribers
Método subscribe() o attach()
Método unsubscribe() o detach()
Método publish() o notify()
Aquí dejo el diagrama simple de como funciona esta versión:
Patrón de diseño publicador/suscriptor simplificado
El publicador/suscriptor se parece más a los eventos del DOM y a eventos personalizados, pero no deja de ser el patrón de diseño Observador. Ademas, como observadores, podemos suscribirnos a más de una actividad o evento.
En el ejemplo, el método suscribe agrega la función observadora, esta última se ejecuta cuando la actividad click es publicada.
En conclusión, el patrón de diseño observador es muy útil, se puede modificar o adecuarlo a ciertas necesidades, un ejemplo es la variacion publicador/suscriptor. Se usa en:
ReactveX.
Librerias y frameworks de componentes web tales como angular, react, lit, vue, svelte utilizan este patrón para su bindeo de datos.
Navegadores web cuando usamos eventos
Node.js cuando utilizamos EventEmitter al recibir una petición a nuestro servidor o al leer un archivo del disco duro.
Flux y redux para manejar cambios en el estado de nuestra aplicación.
Para crear un servidor web en node.js, primero, ¿Qué es node.js?, tomando la definición del sitio oficial, Node.js®es un entorno de ejecución para JavaScript construido con el motor de JavaScript V8 de Chrome. Node.js usa un modelo de operaciones E/S sin bloqueo y orientado a eventos, que lo hace liviano y eficiente. El ecosistema de paquetes de Node.js, npm, es el ecosistema más grande de librerías de código abierto en el mundo.
Vamos a describir la parte que nos interesa, Node.js es un programa, V8 es un motor de javascript de código abierto creado por Google, por lo que también lo hace un programa, V8 está escrito en C++, y la tarea de V8 es tomar código Javascript y convertirlo a código máquina (compilar código), pero lo que lo hace especial para nuestros fines es que puede ser embebido dentro de otros programas, lo que permite que V8 esté embebido en Node.js, V8 por así decirlo es el punto de partida para toda la funcionalidad de Node.js.
Node.js también está escrito en C++ y utiliza la API de V8 para agregarle características y funcionalidades nuevas a Javascript. Estas nuevas funcionalidades permiten tener acceso al sistema de archivos y carpetas, nos permite crear un servidor TCP y http, además de acceso a POSIX, o sea, a toda la funcionalidad del sistema operativo donde se encuentre instalado.
Node.js proporciona la sintaxis Javascript para crear programas que tengan acceso a las características del sistema operativo donde sé está ejecutando.
Con esto podemos razonar que con Node.js podemos crear un servidor web, para crearlo, vamos a utilizar NPM (Node Package Manager) y express.js un frawework web.
Vamos a crear una nueva carpeta llamada mi-servidor-web, luego accede a esta carpeta con:
$ cd mi-servidor-web
Ahora vamos a iniciar el proyecto utilizando el siguiente comando:
$ npm init
La línea de comandos nos pedirá algunos datos, puedes dar “enter” a todos si quieres, te muestro un ejemplo:
Press ^C at any time to quit.packagename: (mi-servidor-web)version: (1.0.0)description: Mi primer servidor webentry point: (index.js)test command:git repository:keywords:author: Jaime Cervantes<jaime.cervantes.ve@gmail.com>license: (ISC)About to write to /home/jaime/develop/node.js/mi-servidor-web/package.json:{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC"}Is this ok? (yes)
npm init nos genera un archivo package.json:
{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC"}
Este archivo contiene la información anteriormente proporcionada y además se encarga de controlar los paquetes que instalamos para nuestro proyecto. Por ejemplo, para poder crear nuestro servidor rápidamente, vamos a instalar un paquete llamado express.js de la siguiente manera:
$ npm install express --save
Este comando instala express.js y además actualiza nuestro archivo package.json gracias al parámetro --save en la propiedad dependencies:
{"name": "mi-servidor-web","version": "1.0.0","description": "Mi primer servidor web","main": "server.js","scripts": {"test":"echo \"Error: no test specified\" && exit 1"},"author": "Jaime Cervantes <jaime.cervantes.ve@gmail.com>","license": "ISC","dependencies": {"express":"^4.16.2"}}
Ya teniendo express instalado, vamos a crear nuestro servidor web creando el archivo ./mi-servidor-web/index.js:
const express =require('express');const app =express();app.use(express.static(__dirname +'/public/'));app.listen('3000',function(){console.log('Servidor web escuchando en el puerto 3000');});
Hay una parte importante que nos permitirá ver el funcionamiento de nuestro servidor web:
app.use(express.static(__dirname +'/public/'));
Esta línea le indica a nuestro servidor que cuando un usuario haga una petición de archivos estáticos, por ejemplo, http://localhost:300/index.html enviará como respuesta el contenido de ./public/index.html.
Vamos a crear la carpeta public y el archivo index.html con el editor de nuestro preferencia o en línea de comandos si lo deseas. Agregamos el siguiente contenido a nuestro archivo index.html:
<!DOCTYPE html><htmllang="es"><head><metacharset="UTF-8"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>Mi primer servidor web</title></head><body><h1>HOLA, mi primer servidor web</h1></body></html>
Para ejecutar nuestro servidor nos posicionamos dentro de nuestra carpeta mi-servidor-web y ejecutamos el siguiente comando:
$ node index.js;
Veremos este mensaje en nuestra consola:
Servidor web escuchando en el puerto 3000
Por último abrimos nuestro navegador web y obtendremos nuestro index.html como la imagen de abajo, utilizando http://localhost:3000 o http://localhost:3000/index.html:
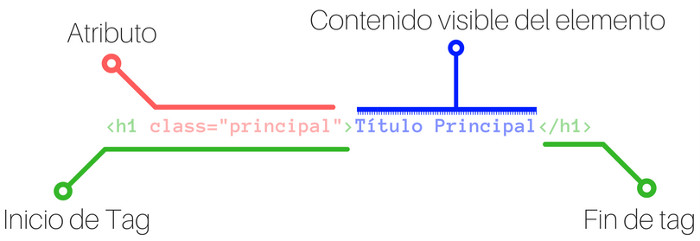
En HTML, los atributos juegan un papel importante porque permiten definir cierta configuración o comportamiento a los elementos HTML, permitiendo obtener diferentes resultados.
Esta publicación es la segunda parte de una serie de publicaciones sobre ¿Cómo puedes crear tu primera página web?, aquí puedes encontrar la primera parte.
En la primera parte vimos como tener las etiquetas(tags) básicas para tu página web, ahora veremos que son los atributos y CSS.
Primera recordemos como es una etiqueta o tagcon la siguiente imagen.
Observando la imagen aprendemos la sintaxis para agregar atributos, es la parte de color rojo, en este caso classes el atributo, seguido de un signo de =y luego entre comillas el valor que queremos asignarle.
Veamos los atributos starty reversedpara una lista ordenada:
Otros atributos no necesitan algún valor, porque su solo presencia es suficiente, uno de ellos es el atributo reversedy open.
Ahora debemos tomar en cuenta que no todos los atributos son aplicables a todas las etiquetas, los atributos reversedy startson atributos específicos para listas ordenadas, es decir, la etiqueta <ol></ol>y no tienen ningún efecto en otros elementos.
Con lo anterior en cuenta podemos discernir que existen atributos Globalesy No globales, los atributos Globalestienen efecto sobre todas las etiquetas, mientras los No Globalessolo a un grupo de etiquetas o a veces solo a una etiqueta en específico.
Entender que atributos son globales es de mucha ayuda, aun así no hay prisa en aprenderlos de memoria, siempre que tengas dudas revisa la lista de atributos globales aquí.
¿Qué es CSS?
Recordemos que…
HTML permite crear el contenido de nuestro página o aplicación de manera organizada. CSS se encarga de la apariencia visual del contenido generado por HTML, con CSS podemos establecer el diseño, colores, tamaño de letra, dimensiones de cada elemento, posiciones y alineados, bordes, sombras y demás características de diseño. Y finalmente Javascript te permite interactuar dinamicamente con la aplicación, claro ejemplo del uso de Javascript son las notificaciones de facebook, el chat de este mismo, cuando damos me gusta, creamos una publicación o escribimos un comentario.
La sintaxis principal de CSS se llama regla. Una regla se comforma de 2 partes, selectory declaración.
Un selectorpermite seleccionar uno o más elementos HTML de nuestra página. CSS es otro lenguaje diferente a HTML, así que el selector de ejemplo no llevan los signos mayory menorque, el selector NO es así <p>.
Cada declaraciónpuede tener uno o más pares de propiedad: valor;, cada par de propiedad: valor;realiza un cambio visual en los elementos seleccionados por el selector.
Los atributos también son muy utiles a la ahora de agregar estilos y diseño de una página web, esto se debe a que la sintaxis del selectortambién hace uso de los atributos para seleccionar uno o más elementos.
Los estilos se pueden agregar usando la etiqueta <style></style>, y esta etiqueta puede existir dentro del <body>o <head>.
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Mi primera página web</title>
<!-- Agrgando estilos dentro de HEAD -->
<style>
p { font-size: 12px; color: #555555; }
</style>
</head>
<body>
<!-- Agreando estilos dentro de BODY -->
<style>
p { font-size: 12px; color: #555555; }
</style>
</body>
</html>
Lo más recomendable es poner nuestros estilos en un archivo aparte con extensión .csse importarlo desde nuestro código html dentro del elemento <head>usando la etiqueta <link>.
Con lo que sabemos de CSS veamos un ejemplo de lo que podemos conseguir:
En la primera regla vemos que el selector es html, con esto sabemos que al elemento html se le van a aplicar estilos. También sabemos que dentro de htmlexisten las demas etiquetas que completan nuestra página como elementos hijos.
Una de las propiedades más comunes es font-size, la cual define el tamaño de la letra del texto. El valor de esta propiedad se define con un número y una unidad, en este ejemplo la unidad es pxque quiere decir pixel.
Al elemento htmlse le llama muchas veces rooto raízy en la mayoría de los navegadores web tiene un font-size: 16pxpor defecto. En este caso el valor por defecto lo estamos disminuyendo 2 pixeles.
html {
font-size: 14px;
}
Existen más unidades, rem, em, %, vhy vwque veremos a detalle más adelante.
Después tenemos nuestro selector body, en la declaración se define el tipo de letra o fuente con la propiedad font-familyy las fuentes se establecen entre comillas, las únicas fuentes que pueden no llevar comillas porque son un estándar en los navegadores web son serif, sans-serif, monospace, cursivay fantasy.
Cada nombre de fuente es separada por una coma(,), de esta manera el navegador va tomando de izquierda a derecha el tipo de fuente, si no existe la primera fuente en tu computadora, va por la segunda y así sucesivamente hasta encontrar una existente.
body {
/*
* ESTO ES UN COMENTARIO:
* Fuentes estandar disponibles en el navegador:
* serif, sans-serif, monospace, cursive, fantasy
* Estas no llevan comillas
*/
font-family: "Helvetica", "Verdana", "Arial", sans-serif;
}
Ya mencionamos que CSS significa Hoja de Estilo en cascada, la parte de cascadase refieren a la herenciay la precedenciade las reglas que definimos, en el caso de font-familyagregado al elemento body, esta propiedad la heredan todos los elementos hijos, por lo que todo nuestra página tendrá el mismo tipo de letra.
Otra propiedad es line-height, la cual define el espacio vertical de las líneas de un texto, podemos notar su funcionamiento en el primer y segundo párrafo, line-height: 1y line-height: 2respectivamente.
Para seleccionar el segundo párrafo ocupamos el atributoid, este atributo debe ser único por cada elemento, no se debe repetir, este selector siempre selecciona un solo elemento.
Dentro de la declaración de propiedades tenemos una propiedad llamada margin-topesta propiedad define la separación superior del segundo párrafo con el primero.
Algo interesante es que el valor es 2rem, la unidad remse refiere al tamaño de fuente del elemento raíz(root), nuestro elemento raíz es htmly como tamaño de letra le definimos anteriormente con 14pxpor lo que margin-topseria igual a 28px. Esta unidad de medida remnos permite definir tamaños relativos al tamaño de la fuente raíz.
Luego en las listas ordenadas tenemos las propiedades padding-top, padding-right, padding-bottomy padding-left. Estas propiedades definen el espacio que existe entre los bordes de un elemento y su contenido. Dado que el selector es olnos permite seleccionar todas las listas ordenadas de nuestra página.
Ahora tenemos el selector .contorno, donde se define la propiedad border, el cual nos permite resaltar el borde de un elemento, su sintaxis es el grosor del borde, el tipo y por último el color. Con esta regla podemos definir un borde verde a todos los elementos que tengan dentro del atributoclassel valor contorno.
.contorno {
border: 1px solid green;
}
Otra propiedad de gran ayuda es list-style-positionla cual define la posición de la numeración o viñetas de una lista. Dado que el selector es li, nos permite seleccionar todas los elementos de listas de nuestra página.
li {
list-style-position: inside;
}
Más abajo tenemos un selector utilizando el atributoidde la primera lista. En la declaración de propiedades se define el color de fondo con background-color: lightblue.
Luego tenemos otro selector que usa el atributoclass, pero un valor de classsi puede ser utilizado en más de un elemento, esto quiere decir, que este selector nos permite seleccionar todos los elementos de nuestra página web que dentro del atributo classtenga el valor green.
Es importante mencionar que el atributo classpuede tener más de un valor separado por un espacio en blanco.
<ol class="green contorno"></ol>
Por último tenemos un elemento detailscon el atributo opensin ningún valor, su sola presencia indica que ese elemento esta desplegadoo abiertoy cuando está desplegado su color de fondo cambia a azul claro. La notación para atributos que no son idni classes la de corchetes [nombreAtributo].

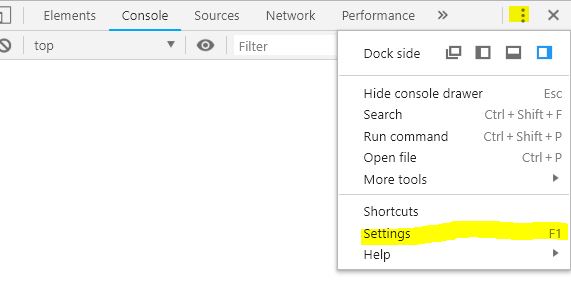
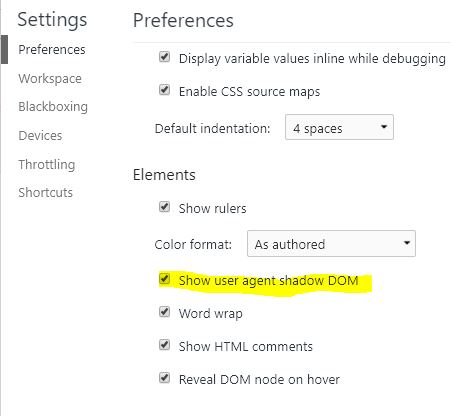
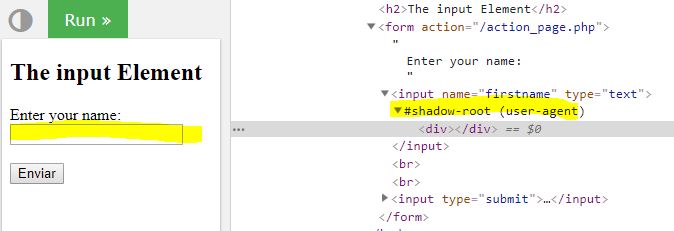
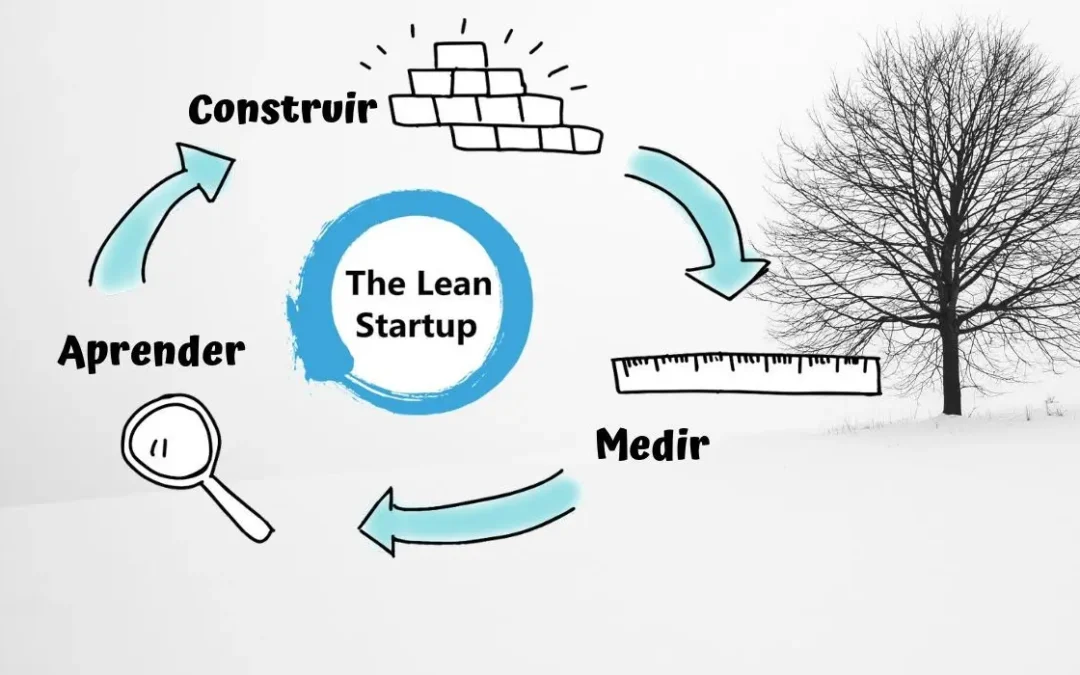
 y Producto (Optimizar)")